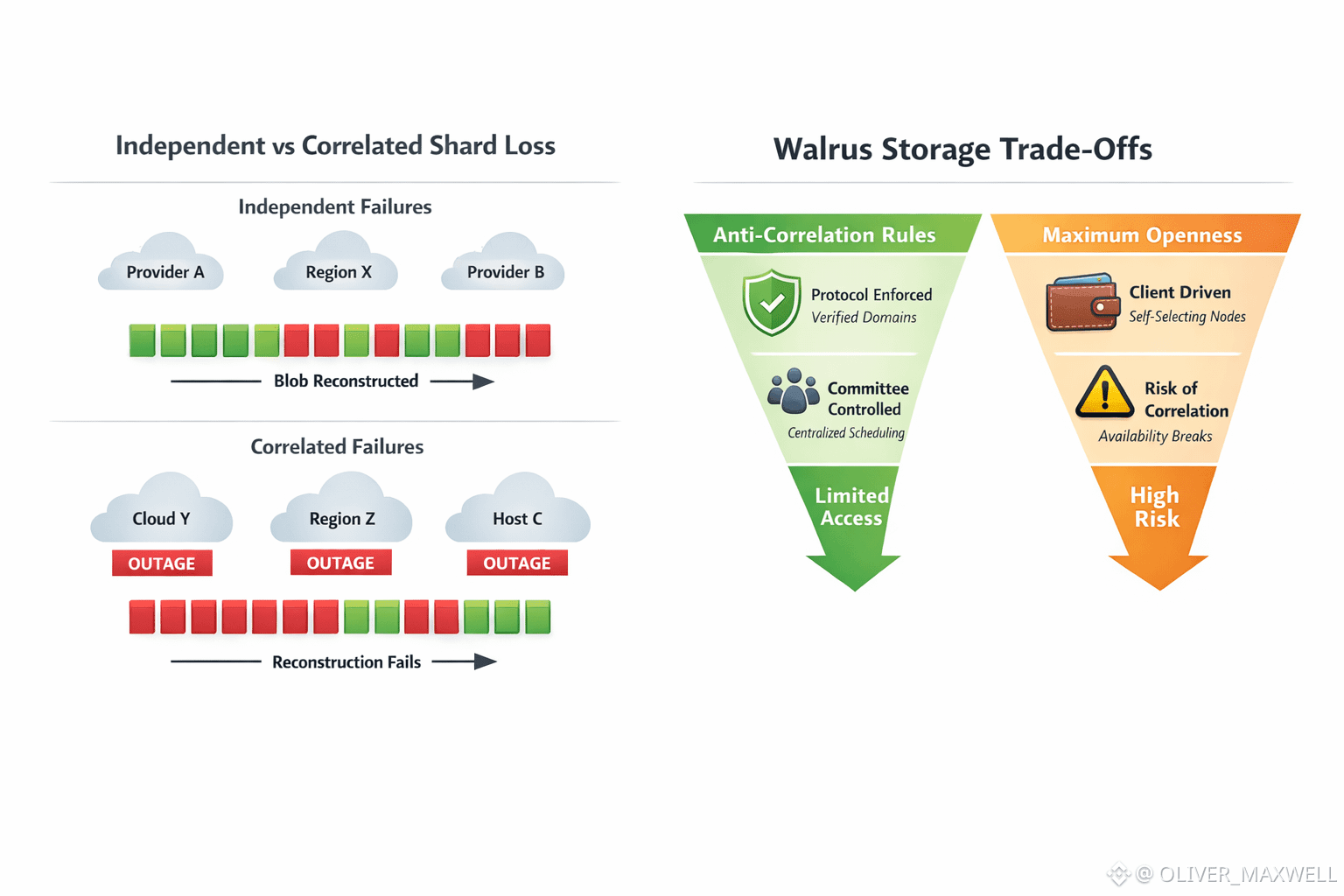
Walrus’ headline resilience, reconstructing a blob even after losing roughly two-thirds of its slivers, only holds if sliver loss is independent across failure domains like provider, region, and operator control. I only buy the math if that independence assumption is enforced or at least observable, because real storage operators do not fail independently. They cluster by cloud provider, by region, by hosting company, and sometimes under the same operational control plane, and that clustering is the real risk.
In the clean model, slivers disappear gradually and randomly across a diverse set of operators, so availability degrades smoothly. In the real model, outages arrive as correlated shocks where many slivers become unreachable at once, then the reachable sliver count drops below the decode threshold, and reads fail because reconstruction is no longer possible from the remaining set. The threshold does not care why slivers vanished. It only cares about how many are reachable at read time, and correlated loss turns a resilience claim into a step function.
This puts Walrus in a design corner. If it wants its resilience claims to hold under realistic correlation, it has to fight correlation by enforcing placement rules that spread slivers across independent failure domains. But the moment you enforce that, you have to define the enforcement locus and the verification surface. If the protocol enforces it, nodes must present verifiable identity signals about their failure domain, and the network must reject placements that concentrate slivers inside one domain. If clients enforce it, durability depends on wallets and apps selecting diverse domains correctly, which is not an enforceable guarantee. If a committee enforces it, you have introduced scheduling power, which pressures permissionlessness.
If Walrus refuses to enforce anti-correlation, the alternative is to accept rare but catastrophic availability breaks as part of the system. Users will remember the marketing number and ignore the failure model until a clustered outage removes a large fraction of slivers from a single blob at once. At that moment the failure is not confusing. It is the direct result of placing too many slivers inside the same correlated domain and then crossing the decode threshold during a shock.
I do not think this is fatal, but it is a real trade-off. Either Walrus leans into anti-correlation and becomes more constrained in who can store which slivers, or it stays maximally open and accepts tail-risk events that break availability guarantees. There is no free option where you get strong resilience and pure permissionlessness under clustered infrastructure realities, because independence is a property that must be enforced, measured, or it does not exist.
This thesis is falsified if Walrus can publish placement and outage metrics showing that correlated infrastructure shocks do not push blobs below reconstruction thresholds without relying on a privileged scheduler. Until then, I see its headline resilience as a bet that correlation will not matter often enough to force uncomfortable governance choices.

