
#Neuraxon Academia de Inteligencia — Volumen 10
Por el Equipo Científico Qubic

Si construimos un sistema artificial y queremos saber si es inteligente, ¿qué es lo que medimos exactamente? Pensamos que sabemos cuando escuchamos que ChatGPT-5 anuncia que ha vencido a DeepSeek y luego que Claude barre con Gemini.
Pero la pregunta sigue ahí, intacta. Medir la inteligencia artificial no es medir velocidad o temperatura. No tenemos una unidad de medida, por extraña que parezca.
En psicología hemos estado lidiando con este problema durante más de un siglo. La inteligencia artificial ha estado en ello durante una década. Y lo hace con prisa, con mucho dinero en juego y con una tentación constante: declarar victoria.
El factor g: Un solo número para resumir la inteligencia general
A principios del siglo XX, Charles Spearman se dio cuenta de que cuando un niño se desempeñaba bien en una materia, tendía a hacerlo bien en las demás, incluso si eran materias sin relación aparente. Las puntuaciones se correlacionaban entre sí, todas positivamente. Llamó a ese patrón el manifold positivo, y dedujo que debe haber un factor latente común detrás de todas esas habilidades dispares: el factor g, o inteligencia general (Spearman, 1904).
La idea es seductora. Si todas las pruebas cognitivas cargan en un solo factor, basta con extraer ese factor a través del análisis de factores para tener una medida resumida de capacidad general. En la práctica humana, ese primer factor suele explicar entre el 40 y el 50 % de la varianza en el rendimiento (Detterman & Daniel, 1989; Deary et al., 2009).
Pero cuidado, porque aquí yace la primera trampa. El factor g es poblacional. No mide al individuo, sino la varianza dentro de los individuos (Hernández-Orallo et al., 2021). Decir que un sujeto específico tiene tanto g es, estrictamente hablando, un error. g emerge al comparar muchos sujetos, no al examinar uno. Al igual que la personalidad, eres el más extrovertido de tu grupo de edad. Y sigues siéndolo a los 50 en relación a tu grupo, incluso si en intensidad eres menos extrovertido que a los 20.
¿Qué mide realmente el CI? Comprendiendo las puntuaciones de inteligencia
Pero entonces, ¿qué mide el CI?
Mide una posición relativa. La escala está calibrada en una muestra con media 100, desviación estándar 15. Un CI de 130 no es una cantidad absoluta de inteligencia almacenada en la cabeza de alguien; es la afirmación de que esta persona está dos desviaciones estándar por encima de la media de su grupo normativo. El número está asociado al individuo, sí, pero su significado es poblacional. Es una posición en un ranking, no un contenido.
Tu altura es absoluta: mides 180 centímetros aunque seas el último ser humano en la Tierra. Tu CI no lo es: estar por encima de la media requiere una media, y una media requiere otros. Nadie puede ser más inteligente que la media en una isla desierta.
Ahora se entiende por qué transferir esto a la IA es tan delicado. Cuando alguien calcula un g para un conjunto de modelos de lenguaje grandes (LLMs), ese factor es un artefacto del conjunto que eligieron. Estamos midiendo una posición en una tabla, y lo presentamos como si fuera una propiedad interna del sistema.
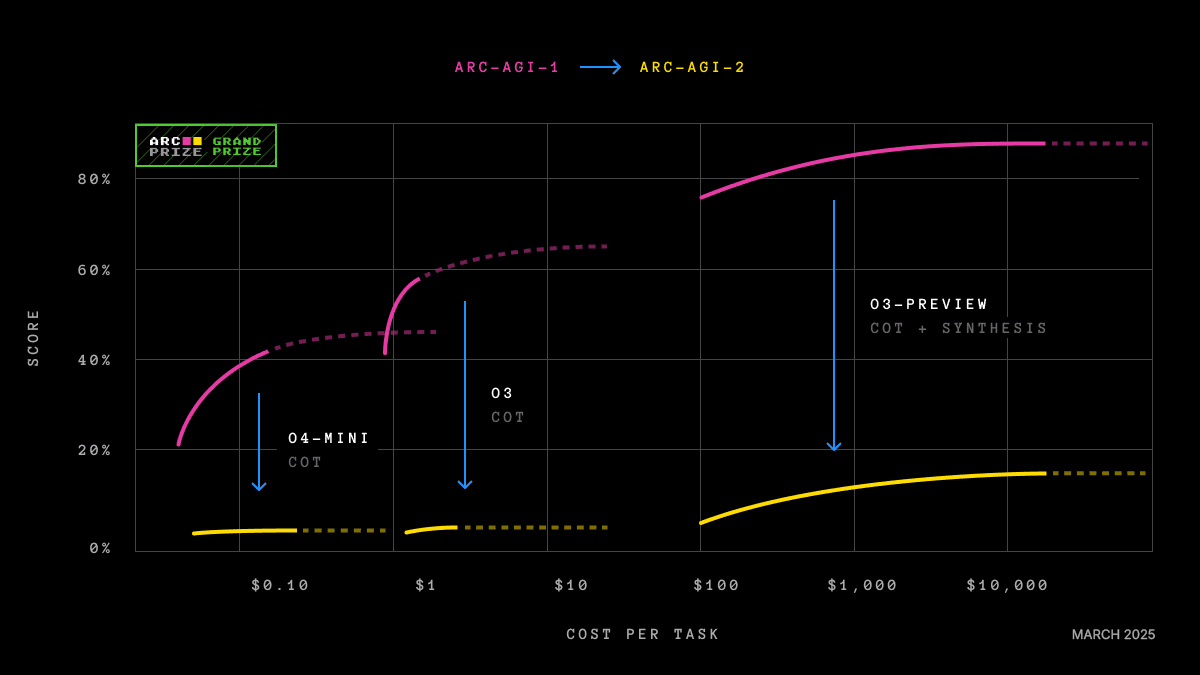
Aplicando el factor g a la inteligencia artificial: una tentación peligrosa
La tentación de transferir todo esto a la IA era irresistible. Gignac y Szodorai propusieron que, si el rendimiento de los modelos en diversas tareas se correlaciona positivamente, debería ser posible identificar un factor general de capacidad en los sistemas artificiales también. Y de hecho, varios trabajos recientes aplican análisis de factores a baterías de pruebas en LLMs y encuentran un factor g unidimensional que se mantiene estable a través de modelos, baterías y métodos de extracción (Ilić, 2023). Suena como una confirmación. Es sabio ser sospechoso.
La aparición de un primer factor dominante no prueba que exista una capacidad general análoga a la humana. Prueba que las puntuaciones de esos modelos co-varían. Y co-varían por una razón muy superficial: comparten arquitectura, comparten corpus de entrenamiento, comparten recetas de optimización. Un modelo grande y bien entrenado hace todo mejor que uno pequeño y mal entrenado, en todas las tareas a la vez. Eso es suficiente para fabricar un hermoso manifold positivo que no nos dice nada sobre la generalidad cognitiva. Nos dice sobre la escala de cómputo. CUIDADO: El factor que extraemos puede ser simplemente un factor de tamaño disfrazado como inteligencia.
El cerebro, además, no concentra la inteligencia en un solo módulo. Una multitud de subsistemas especializados procesan en paralelo y, cuando una pieza de información gana la competencia, se vuelve globalmente accesible para el resto del sistema, que luego puede recombinarla para nuevos propósitos (Baars, 1988; Dehaene & Changeux, 2011). Lo que llamamos generalidad es disponibilidad global: poner una pieza aprendida en un contexto al servicio de un problema en otro. No es un número escalar almacenado; es un patrón de acceso e integración. Este es el tipo de arquitectura funcional que Neuraxon intenta emular: subsistemas modulares con dinámicas de tiempo continuo y plasticidad de múltiples escalas temporales, en lugar de un transformador monolítico.
François Chollet y el enfoque moderno: Midiendo lo que aún no sabes hacer
Contra el legado psicométrico, François Chollet propuso en 2019 un giro conceptual. Su argumento, en Sobre la medida de la inteligencia, es que estábamos midiendo lo incorrecto.
Los benchmarks tradicionales de IA recompensan habilidades, competencias específicas en tareas concretas. Pero una habilidad se puede comprar con datos y cómputo: basta entrenar lo suficiente en una tarea para dominarla. La inteligencia, sostiene Chollet, no es habilidad, sino eficiencia en la adquisición de habilidades: cuánto aprendes de lo poco, al enfrentar una tarea genuinamente nueva (Chollet, 2019).
La inteligencia es lo que haces cuando no sabes qué hacer.
Esta distinción lo cambia todo. Un sistema que resuelve un millón de problemas porque ha visto diez millones de similares no es inteligente. Un sistema inteligente es aquel que, enfrentándose a un problema para el cual no pudo prepararse, descubre la estructura y se adapta con pocos ejemplos. La medida deja de ser el resultado final y se convierte en la pendiente de aprendizaje.
ARC-AGI: El benchmark que evalúa el razonamiento genuino de la IA
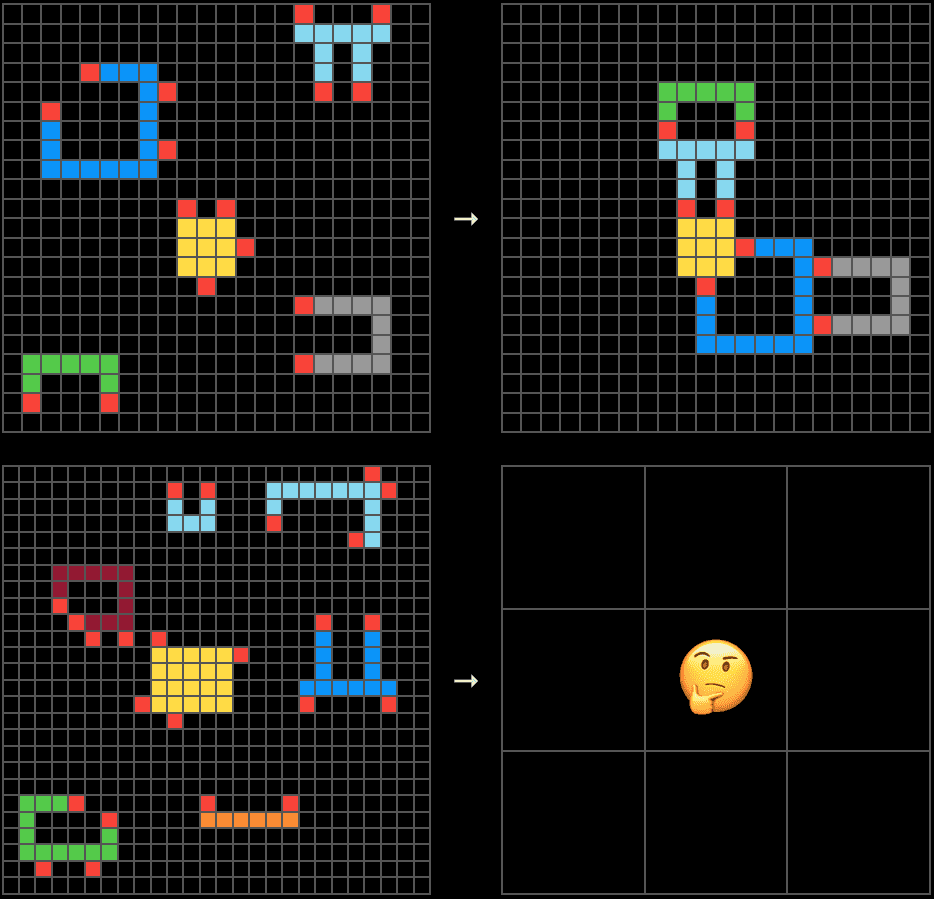
ARC-AGI nació de esa idea, y su versión más reciente, ARC-AGI-3, la lleva más allá. No es un test de preguntas y respuestas. Es un conjunto de entornos interactivos, como mini-videogames, en los que el agente explora un mundo desconocido, deduce cuál es el objetivo sin que se le diga en lenguaje natural, construye un modelo del entorno y adapta su estrategia paso a paso (ARC Prize, 2025).
Los principios de diseño son explícitos: entornos 100 % solucionables por humanos, sin conocimiento pre-cargado o instrucciones ocultas, y con suficiente novedad para prevenir la memorización. Lo que se puntúa no es acertar, sino la eficiencia en la adquisición de habilidades a lo largo del tiempo.
Es lo opuesto al factor g: en lugar de buscar lo que un sistema ya domina y resumirlo, busca lo que aún no sabe hacer y mide cuánto le cuesta aprenderlo.
Contaminación de datos: por qué las puntuaciones de benchmark de LLM están infladas
La razón última por la cual el enfoque de Chollet importa, y por qué el factor g aplicado a los LLMs es tan resbaladizo, tiene un nombre técnico: contaminación de datos. Si el examen, o algo casi idéntico, estaba en las notas que el estudiante estudió, su nota no mide lo que puede razonar. Mide lo que ha memorizado.
Los modelos de lenguaje se entrenan en libros, foros, repositorios de código, artículos, prácticamente todo el texto disponible. Los benchmarks con los que luego los evaluamos se publican en internet. La conclusión es que fragmentos de las pruebas terminan dentro de los datos de entrenamiento, lo que viola la separación entre entrenamiento y evaluación e infla las puntuaciones (Xu et al., 2024; Deng et al., 2024). Auditorías empíricas han detectado niveles de contaminación que oscilan entre el 1 % y hasta el 45 % en benchmarks ampliamente utilizados, y el problema crece con el tiempo (Li et al., 2024).
No es un problema menor de un par de preguntas filtradas. En benchmarks como MMLU o GSM8K, parte de lo que interpretamos como razonamiento puede ser pura memorización (Chen et al., 2025). Cuando se aplican técnicas de descontaminación que reescriben los elementos filtrados sin alterar su dificultad, la precisión cae: en un estudio, 22.9 % en GSM8K y 19.0 % en MMLU (Zhu et al., 2024).
Los elementos parafraseados, o incluso los traducidos a otro idioma, evaden los detectores de superposición superficial y continúan inflando los resultados (Yang et al., 2023; Yao et al., 2024). Las soluciones habituales (parafrasear, traducir, ajustar el contexto) se asumen como efectivas sin haber sido validadas rigurosamente. Y para la mayoría de los modelos abiertos ni siquiera podemos verificar nada, porque sus datos de entrenamiento no se publican. Estamos calificando exámenes sin saber qué estudió el estudiante.
Aquí se entiende por qué ARC-AGI eligió el camino que eligió. Un entorno interactivo, novedoso, sin instrucciones en lenguaje natural y diseñado para prevenir la memorización a la fuerza es, por construcción, resistente a la contaminación.
Entonces, ¿qué deberíamos medir para evaluar la inteligencia de la máquina?
El factor g es una propiedad poblacional que, aplicada a modelos que comparten arquitectura y corpus, corre el riesgo de medir la escala de cómputo y no la generalidad. La lección para quien construya sistemas artificiales no es elegir entre el factor g y ARC-AGI como si fueran equipos rivales. Es entender qué pregunta responde cada uno. Un análisis de factores puede ser útil para describir la estructura interna del rendimiento de un sistema, siempre que no se confunda el primer factor con una esencia de la inteligencia. Y un protocolo de tipo ARC es indispensable para lo que realmente importa: verificar si el sistema generaliza más allá de lo que vio, o simplemente recita.
Cuando evaluamos un sistema solo por su respuesta final, lo estamos midiendo con los ojos cerrados a su dimensión temporal: planificación, actualización de creencias, integración de evidencia a través de muchos pasos. Es exactamente lo que ARC-AGI-3 decidió puntuar, y exactamente lo que un examen estático no puede ver.

Por qué las arquitecturas de IA inspiradas en el cerebro como Neuraxon toman un camino diferente
Si la inteligencia no es un número almacenado, sino la integración eficiente de subsistemas especializados, como sugiere la teoría de integración parieto-frontal (P-FIT) y la disponibilidad global del espacio de trabajo en el cerebro...
Si esa integración es sobre todo un fenómeno temporal, con escalas de tiempo...
Entonces, un sistema construido sobre arquitecturas modulares con esferas funcionales, plasticidad a través de múltiples escalas temporales y dinámicas continuas no necesita ser evaluado pidiéndole que recite respuestas.
La pregunta correcta no es cuántos benchmarks supera, sino con qué eficiencia adquiere nuevo comportamiento, a lo largo del tiempo, en entornos para los cuales no estaba preparado. Esa es la dirección que intenta tomar Neuraxon. Calcular tiempo – es decir, adaptación – no respuestas memorizadas que simulan ser un buen estudiante, cuando en realidad, ya conoce las preguntas.
Referencias
Chollet, F. (2019). Sobre la medida de la inteligencia. arXiv:1911.01547.
Deary, I. J., Penke, L., & Johnson, W. (2009). La neurociencia de las diferencias en la inteligencia humana. Nature Reviews Neuroscience.
Dehaene, S., & Changeux, J.-P. (2011). Enfoques experimentales y teóricos del procesamiento consciente. Neuron, 70(2), 200–227.
Detterman, D. K., & Daniel, M. H. (1989). Correlaciones de pruebas mentales entre sí y con variables cognitivas. Inteligencia.
Gignac, G. E., & Szodorai, E. T. (2024). Definiendo e identificando un factor general de capacidad en los sistemas de IA.
Guttman, L. (1955). La determinación de matrices de puntuación de factores con implicaciones para otros cinco problemas básicos de la teoría de factores comunes. British Journal of Statistical Psychology.
Hernández-Orallo, J., et al. (2021). Inteligencia general desenredada a través de una métrica de generalidad para la inteligencia natural y artificial. Scientific Reports.
Honey, C. J., et al. (2012). Dinámicas corticales lentas y la acumulación de información a lo largo de escalas temporales largas. Neuron, 76(2), 423–434.
Ilić, D. (2023). Revelando el factor de inteligencia general en modelos de lenguaje: Un enfoque psicométrico. arXiv:2310.11616.
Jung, R. E., & Haier, R. J. (2007). La teoría de integración parieto-frontal (P-FIT) de la inteligencia. Behavioral and Brain Sciences.
Spearman, C. (1904). "La inteligencia general" determinada y medida objetivamente. American Journal of Psychology, 15, 201–293.
Roberts, M., et al. (2024). Evidencia temporal de contaminación por fechas de corte de entrenamiento.
Schönemann, P. H. (2008). Una respuesta a Mackintosh y algunos comentarios sobre el concepto de inteligencia general. arXiv:0808.2343.
Xu, C., et al. (2024). Contaminación de datos de benchmark en modelos de lenguaje grandes: una encuesta.
Yang, S., et al. (2023). Repensando los benchmarks y la contaminación para modelos de lenguaje con muestras reformuladas.
Zhu, Q., et al. (2024). Descontaminación en el tiempo de inferencia: reutilizando benchmarks filtrados para la evaluación de LLM. Hallazgos de EMNLP 2024.
ARC Prize (2025). ARC-AGI-3: Un benchmark de razonamiento interactivo. Informe técnico.
Explora la serie completa de la Academia de Inteligencia Neuraxon
Este es el Volumen 10 de la Academia de Inteligencia Neuraxon por el Equipo Científico Qubic. Si te estás uniendo a nosotros, explora la serie completa para construir una comprensión total de la ciencia detrás de Neuraxon, Aigarth y el enfoque de Qubic hacia la inteligencia artificial descentralizada inspirada en el cerebro:
NIA Volumen 1: Por qué la inteligencia no se calcula en pasos, sino en tiempo — Explora por qué la inteligencia biológica opera en tiempo continuo en lugar de pasos computacionales discretos como los LLMs tradicionales.
NIA Volumen 2: Dinámicas ternarias como un modelo de inteligencia viva — Explica las dinámicas ternarias y por qué la lógica de tres estados (excitatoria, neutral, inhibitoria) importa para modelar sistemas vivos.
NIA Volumen 3: Neuromodulación y IA inspirada en el cerebro — Cubre la neuromodulación y cómo la señalización química del cerebro (dopamina, serotonina, acetilcolina, norepinefrina) inspira la arquitectura de Neuraxon.
NIA Volumen 4: Redes neuronales en IA y neurociencia — Una comparación profunda de redes neuronales biológicas, redes neuronales artificiales y el enfoque de tercer camino de Neuraxon.
NIA Volumen 5: Astrocitos y IA inspirada en el cerebro — Cómo el control astrocítico transforma la plasticidad de la red neuronal a través del marco AGMP en Neuraxon.
NIA Volumen 6: Máquinas conscientes vs. organismos inteligentes: Explicación de la conciencia de IA — Explora la conciencia de IA a través de la lente de la teoría del espacio de trabajo global, la teoría de la información integrada y la codificación predictiva.
NIA Volumen 7: El juego de la vida de Conway, la vida artificial y los ecosistemas digitales — La ciencia detrás de Qubic, Aigarth y la complejidad emergente y criticidad autoorganizada de Neuraxon.
NIA Volumen 8: La criticidad cerebral y la razón de ramificación en redes neuronales y artificiales — Por qué una razón de ramificación cerca de 1 y la criticidad autoorganizada son principios de diseño bioinspirados en Neuraxon.
NIA Volumen 9: Los orígenes del factor g: De la educación y la neurociencia a la inteligencia artificial — Explora los orígenes del factor g a través de la educación, la neurociencia y la IA.
$Qubic es una red descentralizada y de código abierto para tecnología experimental. Para saber más, visita qubic.org. Únete a la discusión en X, Discord y Telegram.