

je regarde OpenLoRA cette fois-ci du côté des coûts.
pas du côté de l'engouement pour l'IA.
pas du côté du token.
même pas le titre “IA décentralisée”.
le côté des coûts.
parce qu'un des problèmes les moins glamours en IA est aussi l'un des plus grands : déployer des modèles coûte cher, surtout quand chaque modèle spécialisé nécessite sa propre configuration de service, mémoire, infrastructure et logique d'évolutivité.
C'est là qu'OpenLoRA devient intéressant.
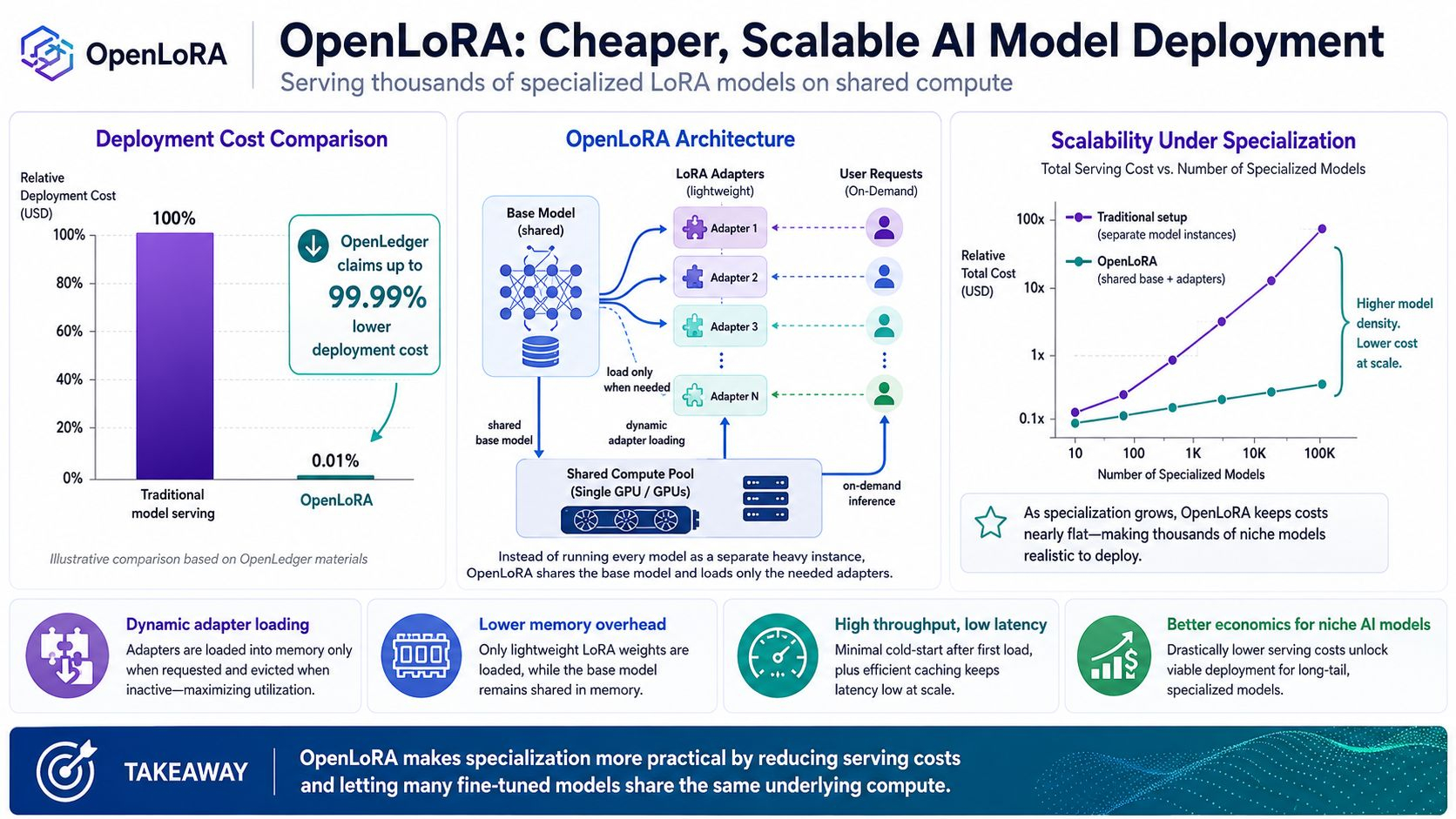
OpenLedger décrit OpenLoRA comme un cadre pour servir des milliers de modèles LoRA affinés sur un seul GPU. Au lieu de charger chaque modèle affiné comme une instance lourde séparée, OpenLoRA utilise le chargement dynamique d'adaptateurs, des modèles de base partagés et une inférence optimisée pour réduire la surcharge mémoire tout en maintenant un débit élevé et une latence faible.
ça semble technique, mais la version simple est la suivante :

OpenLoRA essaie d'empêcher chaque modèle d'IA d'avoir besoin de sa propre machine coûteuse.
Et cela compte parce que l'avenir de l'IA ne sera probablement pas un énorme modèle général qui fait tout. Ce sera de nombreux modèles plus petits et spécialisés formés pour des cas d'utilisation spécifiques : assistants juridiques, analyses médicales, agents de jeux, outils de trading, bots de recherche, agents de support client, copilotes spécifiques à un domaine.
Mais si chacun de ces modèles a besoin d'une infrastructure GPU séparée, l'économie se casse rapidement.
Le blog d'OpenLedger présente OpenLoRA comme un moteur de déploiement conçu pour réduire le coût de lancement des modèles jusqu'à 99,99 %. Ce chiffre est agressif, mais l'idée sous-jacente est claire : la création de modèles n'est que la moitié du problème. Le déploiement est là où de nombreux projets d'IA deviennent trop coûteux à réellement faire fonctionner.
ce qui a attiré mon attention, c'est la logique des adaptateurs.
Les modèles LoRA ne sont pas des modèles complets au sens traditionnel. Ce sont des adaptateurs légers ajustés qui se trouvent au-dessus d'un modèle de base. L'architecture d'OpenLoRA stocke ces adaptateurs et les charge uniquement lorsque nécessaire au lieu de garder tout préchargé dans la mémoire GPU. Ses docs décrivent le chargement dynamique des adaptateurs, la fusion d'adaptateurs à la volée, le routage des requêtes, le streaming de tokens, et des optimisations au niveau de CUDA comme Flash Attention, Paged Attention, et SGMV.
c'est le vrai tour d'efficacité.
Le modèle de base reste partagé.
Le comportement spécialisé provient des adaptateurs. Au lieu de garder des milliers de modèles en cours d'exécution séparément, OpenLoRA allège le processus. Il permet à différents modèles spécialisés de partager les mêmes ressources de base et n'apporte les pièces supplémentaires que lorsque cela est nécessaire.
Ça change l'équation de scalabilité.
Pour les développeurs, cela signifie qu'ils peuvent expérimenter avec des modèles plus spécialisés sans s'inquiéter immédiatement que le coût de déploiement tue l'idée. Binance Academy décrit également OpenLoRA comme le moteur de déploiement d'OpenLedger pour exécuter des modèles d'IA plus rapidement et plus facilement, permettant à des milliers de modèles de fonctionner sur un seul GPU grâce à une meilleure gestion des ressources.
c'est important pour la vision plus large d'OpenLedger.
Parce qu'OpenLedger ne concerne pas uniquement l'entraînement de modèles. Ses docs décrivent la plateforme comme une infrastructure IA-blockchain pour entraîner et déployer des modèles spécialisés utilisant des Datanets détenus par la communauté, avec des téléchargements, des entraînements, des crédits de récompense, la gouvernance, l'inférence, et l'attribution liés au système.

Donc OpenLoRA n'est pas une fonctionnalité de performance isolée.
C'est la couche de déploiement qui rend l'ensemble de l'économie des modèles plus pratique.
Les Datanets aident à produire des données spécialisées.
La Fabrique de Modèles aide à créer ou affiner des modèles.
La Preuve d'Attribution suit qui a contribué à la valeur.
OpenLoRA aide ces modèles à fonctionner réellement à grande échelle.
sans cette dernière partie, tout le système se bloque.
Un modèle qui ne peut pas être déployé à moindres frais n'est pas vraiment utile pour une adoption de masse. Il peut avoir l'air bien dans une démo, mais une fois que les utilisateurs arrivent, les coûts commencent à monter. Plus de requêtes. Plus d'agents. Plus d'adaptateurs. Plus de pression de latence. Plus de demande GPU.
OpenLoRA essaie de rendre cette croissance moins douloureuse.
ma préoccupation cependant :
le chargement dynamique et le partage d'adaptateurs semblent puissants, mais la performance dans le monde réel dépend des schémas de demande. Une architecture propre a l'air bien, mais l'utilisation réelle est plus difficile. Si de nombreux adaptateurs sont utilisés à des moments aléatoires, le système doit rester rapide, organisé et fiable sous pression. Des fonctionnalités comme un chargement plus rapide et l'optimisation aident, mais le vrai test est lorsque des utilisateurs réels créent un trafic lourd.
pourtant, la direction a du sens.
L'argument plus large d'OpenLedger est que l'IA devrait devenir plus ouverte, traçable et monétisable. Mais rien de tout cela ne fonctionne si les modèles spécialisés sont trop coûteux à servir. OpenLoRA attaque le goulet d'étranglement caché : pas « pouvons-nous ajuster le modèle ? » mais « pouvons-nous nous permettre de garder de nombreux modèles vivants en même temps ? »
C'est peut-être la partie négligée.
OpenLoRA ne fait pas que rendre le déploiement de l'IA moins cher.
Il rend la spécialisation plus réaliste.
parce que si des milliers de modèles peuvent partager efficacement du matériel limité, alors de petites équipes, des communautés de niche et des experts de domaine ont une meilleure chance de lancer une IA utile sans avoir besoin de budgets d'infrastructure géants.
et c'est là que l'économie de l'IA d'OpenLedger commence à paraître plus pratique.
pas un gros modèle possédé par une plateforme géante.
de nombreux modèles spécialisés, déployés à moindre coût, évolués efficacement, et reliés aux données et contributeurs qui les ont rendus précieux.
@OpenLedger #OpenLedger $OPEN $MITO

