
OpenLedger pourrait être en train de construire la partie de l'économie de l'IA que personne ne veut vraiment regarder trop longtemps.
La piste de l'argent.
Pas la démo propre. Pas l'interface d'agent avec une UI fluide et de grandes promesses. Pas un autre fil soigné sur la façon dont l'IA et la crypto vont enfin se comprendre ce cycle. J'ai vu suffisamment de ces récits recyclés jusqu'à ce qu'il ne reste plus que du bruit. La plupart d'entre eux commencent par un langage énorme, attirent l'attention, attirent la liquidité, puis finissent par se heurter au même vieux problème : personne ne peut expliquer où la vraie valeur est censée se stabiliser.
OpenLedger pointe au moins vers une vraie plaie.
L'IA crée de la valeur à partir d'un tas de travail invisible. Données. Modèles. Invites. Ajustement fin. Tests. Retours. Travail communautaire. Jugement humain. Tout cela est poussé dans la machine, mélangé, compressé, et ensuite la sortie finale sort propre. Quelqu'un le monétise. Quelqu'un en tire le bénéfice.
La plupart des contributeurs disparaissent.
C'est la partie qu'OpenLedger semble vouloir aborder. Pas d'une manière mignonne "les utilisateurs possèdent leurs données". Cette ligne a été battue à mort. Je veux dire dans un sens plus dur, plus financier. Si l'IA crée quelque chose de précieux, OpenLedger demande qui a réellement aidé à le créer, comment cette contribution est tracée, et si les récompenses peuvent se déplacer en arrière dans le système au lieu de seulement vers le haut vers la plateforme en haut.
Ça a l'air ennuyeux.
Bien.
Beaucoup de choses qui comptent réellement dans la crypto sonnent ennuyeuses avant de devenir évidentes. Règlement. Indexation. Routage de liquidité. Vérification. Conception d'incitations. Personne ne veut parler des canalisations quand le marché chasse n'importe quelle chose brillante qui vient de bouger de 40%. Mais les canalisations sont généralement là où les projets deviennent soit une infrastructure, soit pourrissent tranquillement.
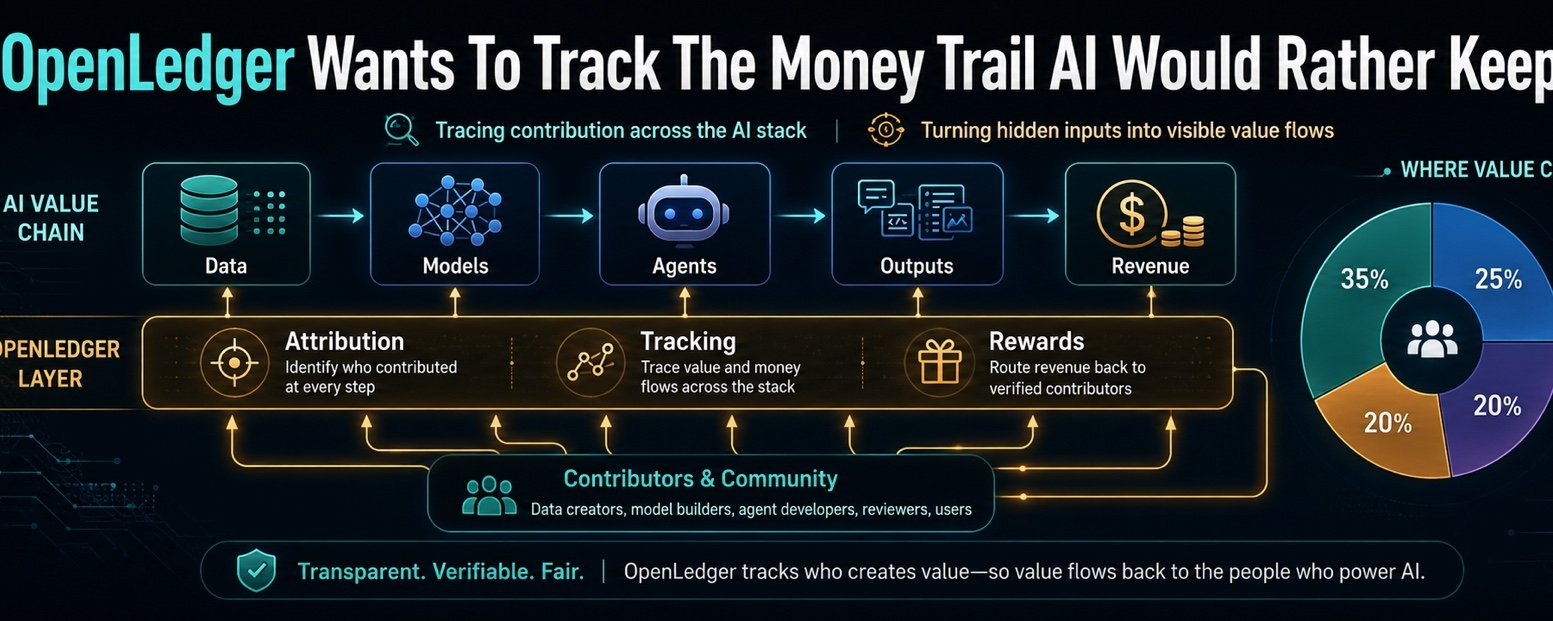
L'idée centrale d'OpenLedger est l'attribution. Si un modèle produit une sortie, ou si un agent IA prend une action, le système doit être capable d'enregistrer ce qui a aidé à façonner ce résultat. Quelles données ont compté. Quel modèle a été impliqué. Quel contributeur a ajouté quelque chose d'utile. Quelle partie de la pile mérite une part si de l'argent sort de l'autre côté.
Phrase simple. Problème brutal.
Parce que l'IA n'est pas propre. Une sortie peut être influencée par des milliers d'entrées. Une action d'agent utile peut dépendre d'un ensemble de données, d'un modèle, d'un flux de travail, d'une structure d'invite, d'un appel d'outil, et d'un travail humain antérieur que personne n'a correctement évalué lorsqu'il est entré dans le système. Une fois que vous commencez à demander qui mérite le crédit, vous ne obtenez pas l'équité tout de suite.
Vous obtenez des frictions.
Vous obtenez des arguments.
Vous obtenez des gens qui regardent la table de paiement et réalisent que la machine a évalué leur travail moins que ce qu'ils ont fait.
C'est là que je commence à faire attention. Pas parce qu'OpenLedger a résolu tout cela. Je doute que quiconque l'ait fait. Je cherche le moment où cela va réellement se casser, parce que c'est là que le projet devient réel ou est exposé. L'attribution est facile à décrire quand tout le monde est encore excité. Ça devient moche quand les récompenses sont en direct, que les contributeurs ne sont pas d'accord, et que le système doit défendre ses propres calculs.
L'angle de l'agent IA rend l'ensemble plus lourd.
Un modèle IA normal vous donne une réponse. Un agent fait quelque chose. Cette petite différence crée beaucoup de problèmes. Une fois que les agents commencent à rechercher, créer, trader, automatiser, dépenser, router des tâches, et toucher à l'activité on-chain, la question n'est plus seulement "qu'est-ce qui a généré cela ?" Cela devient "qui l'a autorisé, qu'est-ce qu'il a utilisé, qui est payé, et qui prend le coup si ça tourne mal ?"
La crypto aime l'autonomie jusqu'à ce que l'autonomie crée une responsabilité.
J'ai déjà vu ce schéma auparavant. Le marché se saoule d'abord sur le concept. Agents autonomes, économies auto-gérées, travailleurs IA, paiements machine à machine, tout ça. Puis les questions ennuyeuses arrivent tard et gâchent la fête. Permissions. Pistes d'audit. Mauvaise exécution. Mauvaises incitations. Exploits. Pression légale. Utilisateurs prétendant avoir compris le risque après coup.
OpenLedger est intéressant car il est plus proche de ces questions ennuyeuses que de la fête.
Ça ressemble moins à un projet essayant de rendre l'IA plus cool et plus à un projet essayant de donner à l'IA une mémoire financière. Un enregistrement de ce qui a été utilisé. Un enregistrement de qui a contribué. Un enregistrement de pourquoi les récompenses ont bougé. Un enregistrement de ce qu'un agent a fait avant que tout le monde ne commence à discuter du résultat.
Ce n'est pas un petit détail.
Mais voici la chose. Un bon problème ne fait pas automatiquement un bon token. La crypto continue d'oublier cela, généralement intentionnellement. Un projet peut être directionnellement correct et être encore un terrible actif pendant longtemps. Peut-être pour toujours. Le marché ne récompense pas la complexité juste parce qu'elle est réelle. Il récompense le timing, la liquidité, les émissions, l'attention, et la capture de valeur claire.
C'est là que je reste prudent.
OpenLedger peut construire quelque chose d'utile et rencontrer encore des difficultés si le token n'est pas suffisamment lié à la demande réelle. Si l'utilisation se produit quelque part dans la pile mais que le token reste juste à proximité comme un logo, alors les détenteurs parient simplement que le marché sera généreux plus tard. J'ai vu ce trade. Cela commence généralement par de la conviction et se termine par des gens expliquant les calendriers de déverrouillage sur Telegram à 3 heures du matin.
Le véritable test, cependant, n'est pas de savoir si l'idée semble importante. Elle l'est.
Le test est de savoir si OpenLedger peut rendre l'attribution crédible lorsque le système a de l'argent réel qui circule à travers lui. Pas d'activité de tableau de bord. Pas de chiffres de campagne. Pas de bruit doux de l'écosystème. Utilisation réelle. Contributeurs réels. Disputes réelles. Paiements réels dont les gens se soucient suffisamment pour se battre.
C'est là que nous découvrons de quoi il s'agit.
Parce que l'attribution n'est pas une caractéristique morale paisible. C'est un couteau. Ça découpe la valeur et dit à tout le monde quelle part ils obtiennent. Certaines personnes se sentiront vues. D'autres se sentiront volées. Un système qui prétend récompenser la contribution doit survivre à la colère des gens qui pensent qu'il les a mesurés de manière erronée.
Et peut-être que c'est le coût caché de la vision d'OpenLedger.
Si ça marche, cela ne rend pas l'économie IA plus fluide. Cela peut la rendre plus honnête, ce qui est différent et probablement plus douloureux. Cela traîne le travail caché dans la couche comptable. Cela rend la chaîne de valeur moins floue. Cela transforme la contribution vague en chiffres. Les chiffres créent des disputes.
Cependant, l'alternative est pire.
L'économie IA actuelle fonctionne trop confortablement sur des entrées invisibles. Les données entrent. Le travail humain entre. La connaissance de la communauté entre. La sortie sort estampillée, monétisée, et polie. Tout le monde applaudit à l'interface pendant que l'histoire d'origine est enterrée quelque part sous les poids du modèle.
OpenLedger essaie de creuser dans cette couche enfouie.
Je ne sais pas si le marché a la patience pour ça. La plupart des jours, il n'en a pas. Le marché veut de la vitesse, des mèmes, de la liquidité, et une raison de croire que la prochaine bougie corrigera la dernière erreur. L'infrastructure demande du temps. L'attribution demande encore plus de temps. Et les marchés de tokens sont terribles à attendre à moins qu'il n'y ait du rendement, du battage médiatique, ou de la peur les maintenant en place.
Ce décalage va être un combat.
OpenLedger pourrait être en avance. Cela pourrait être trop compliqué pour l'attention des particuliers. Cela pourrait construire des rails avant que suffisamment de personnes admettent qu'elles ont besoin de rails. Cela pourrait également découvrir que les grands acteurs de l'IA préfèrent la comptabilité privée, les accords de données privés, et le contrôle privé sur quoi que ce soit d'ouvert ou traçable. Cela ne me choquerait pas. Les plus grands acteurs choisissent rarement la transparence à moins que la pression ne les y force.
Donc je ne traite pas OpenLedger comme un gagnant propre.
Je le traite comme une question sérieuse enveloppée dans une structure de marché risqué.
La question sérieuse est la suivante : si l'IA continue de produire de la valeur à partir de millions d'entrées invisibles, combien de temps l'industrie peut-elle éviter de montrer le reçu ?
Parce qu'éventuellement, quelqu'un demandera qui a rendu la machine utile.
Et peut-être que la réponse inconfortable est que personne ne veut que le livre soit ouvert trop tôt.