J'ai assisté à suffisamment de présentations crypto pour savoir quand une pitch n'est que du vent dans un beau costume. Au début, @OpenLedger semblait être une énième pitch AI-chain essayant de paraître profond. Données, modèles, preuves, utilisateurs, flux de tokens. Ça va. J'ai entendu ce chant. Puis j'ai regardé ce qu'il essaie de lier. C'est là que ça a commencé à devenir moins mignon et plus digne d'un examen approfondi.
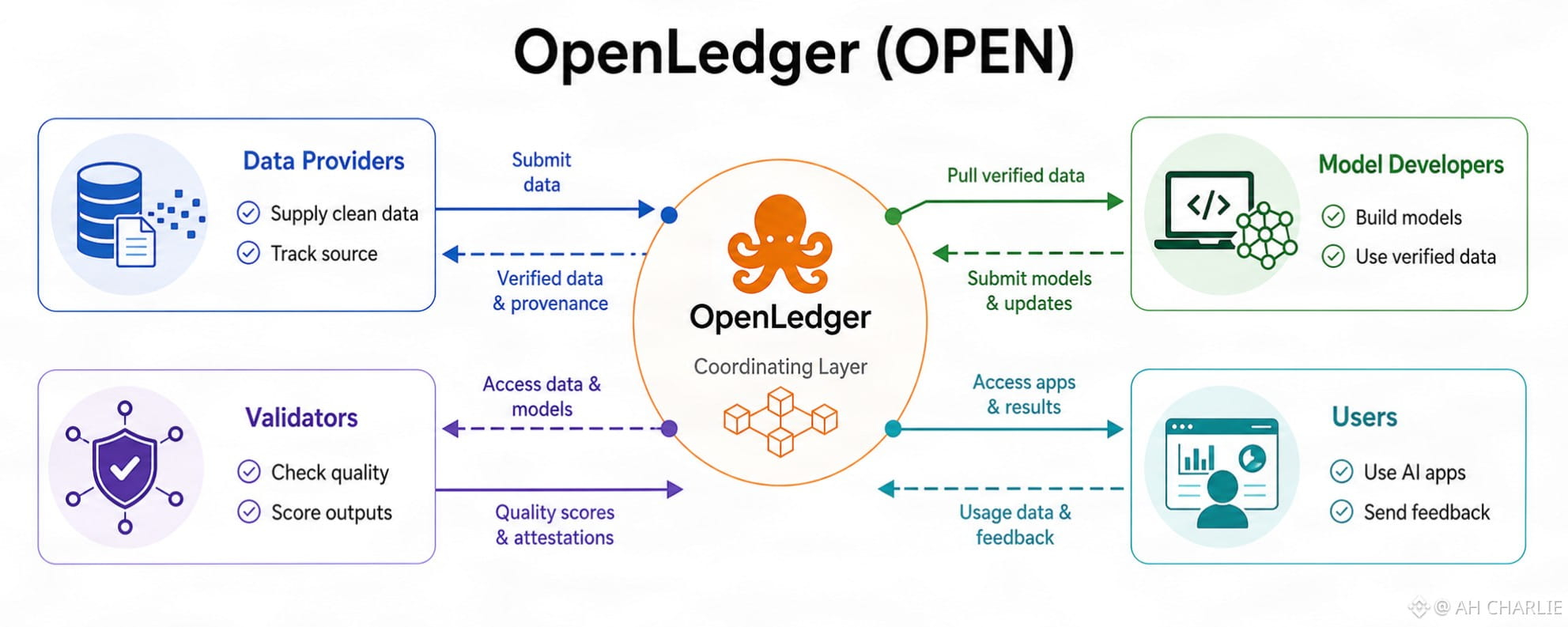
OpenLedger est conçu autour d'un point de douleur évident : l'IA a besoin de données, mais les données brutes en elles-mêmes sont un vrai bazar. Certaines sont périmées. Certaines sont des déchets. D'autres sont bonnes mais difficiles à suivre. Les fournisseurs de données alimentent le système, mais ce carburant a toujours besoin d'un compteur. Avec OpenLedger, les données ne sont pas simplement balancées dans une boîte noire. Elles ont un rôle. Elles peuvent être vérifiées, notées et liées à leur source. Cela compte parce qu'en IA, une mauvaise entrée ne fait pas que perdre du temps. Elle déforme la sortie.
Les devs de modèle sont sur la couche suivante. Ils ne sont pas là pour l'ambiance. Ils ont besoin de données propres, de droits clairs, et d'une manière de construire sans mendier des stacks fermés. OpenLedger leur offre une voie pour accéder aux données de manière plus ouverte tout en gardant une trace de qui a apporté quoi. C'est un gros deal, mais pas de la magie. Ça dépend toujours de la qualité du flux de données, de l'équité des règles, et de savoir si les devs peuvent livrer du travail que de vrais utilisateurs utilisent.
Ils ne sont pas des mascottes. Ce sont des postes de contrôle. Dans ce setup, les validateurs aident à garder les données et le travail de modèle d'une boue de confiance. Ils aident à réviser, vérifier, et tenir le score pour que le réseau ne soit pas juste dirigé par des affirmations bruyantes. Dans l'IA crypto, c'est là que beaucoup de plans échouent. Si personne ne vérifie, le spam gagne. Si les vérifications sont faibles, de la fausse valeur s'infiltre.
Les utilisateurs sont à la fin de la chaîne, mais ils ne sont pas juste des points d'extrémité. Ils sont le test de stress final. Si les apps construites sur OpenLedger n'aident pas les utilisateurs à faire un vrai travail, toute la boucle devient molle. Les fournisseurs de données ne s'en soucieront pas. Les devs ne resteront pas. Les validateurs n'auront pas beaucoup de sens. $OPEN peut être au centre de cette boucle, mais un token seul ne peut pas sauver un usage faible.
L'idée d'OpenLedger a du sens parce qu'elle essaie de lier quatre groupes qui se déplacent souvent comme des étrangers. Les fournisseurs de données veulent du crédit. Les devs veulent des trucs bruts qu'ils peuvent utiliser. Les validateurs veulent des règles qu'ils peuvent faire respecter. Les utilisateurs veulent des outils qui ne gaspillent pas de temps.
Mais si OpenLedger peut garder cette boucle serrée, équitable, et difficile à manipuler, il a une vraie chance d'être plus qu'un discours sur la chaîne AI. Pas à cause du buzz. Parce que de bons marchés ont besoin de canalisations, de vérifications, et de demande réelle. C'est là que je suis aux aguets.
