
#Neuraxon Académie d'Intelligence — Volume 10
Par l'équipe scientifique Qubic

Si on construit un système artificiel et qu'on veut savoir s'il est intelligent, qu'est-ce qu'on mesure exactement ? On pense savoir quand on entend que ChatGPT-5 annonce avoir battu DeepSeek et ensuite que Claude sweep Gemini.
Mais la question reste là, intacte. Mesurer l'intelligence artificielle, ce n'est pas mesurer la vitesse ou la température. Nous n'avons pas d'unité de mesure, aussi étrange que cela puisse paraître.
En psychologie, nous traitons ce problème depuis plus d'un siècle. L'intelligence artificielle s'attaque depuis une décennie. Et elle le fait rapidement, avec beaucoup d'argent en jeu et avec une tentation constante : déclarer la victoire.
Le facteur g : Un seul nombre pour résumer l'intelligence générale
Au début du 20ème siècle, Charles Spearman a réalisé que lorsque un enfant performait bien dans une matière, il avait tendance à bien performer dans les autres, même s'il s'agissait de matières sans relation apparente. Les scores corrélés entre eux, tous positivement. Il a appelé ce modèle le manchon positif, et il a déduit qu'il devait y avoir un facteur latent commun derrière toutes ces capacités disparates : le facteur g, ou intelligence générale (Spearman, 1904).
L'idée est séduisante. Si tous les tests cognitifs se chargent sur un seul facteur, il suffit d'extraire ce facteur par une analyse factorielle pour avoir une mesure résumée de la capacité générale. Dans la pratique humaine, ce premier facteur explique généralement entre 40 et 50 % de la variance de performance (Detterman & Daniel, 1989 ; Deary et al., 2009).
Mais attention, car c'est ici que se trouve le premier piège. Le facteur g est populationnel. Il ne mesure pas l'individu, mais la variance au sein des individus (Hernández-Orallo et al., 2021). Dire qu'un sujet spécifique a tant de g est, strictement parlant, une erreur. Le g émerge lorsque l'on compare de nombreux sujets, pas lorsqu'on examine un seul. Comme la personnalité, vous êtes le plus extraverti de votre groupe d'âge. Et vous le restez à 50 par rapport à votre groupe, même si en intensité vous êtes moins extraverti qu'à 20.
Que mesure vraiment le QI ? Comprendre les scores d'intelligence
Mais alors, que mesure le QI ?
Il mesure une position relative. L'échelle est calibrée sur un échantillon avec une moyenne de 100, un écart-type de 15. Un QI de 130 n'est pas une quantité absolue d'intelligence stockée dans la tête de quelqu'un ; c'est l'affirmation que cette personne est deux écarts-types au-dessus de la moyenne de son groupe normatif. Le nombre est attaché à l'individu, oui, mais sa signification est populationnelle. C'est une position dans un classement, pas un contenu.
Votre taille est absolue : vous mesurez 180 centimètres de haut même si vous êtes le dernier être humain sur Terre. Votre QI ne l'est pas : être au-dessus de la moyenne nécessite une moyenne, et une moyenne nécessite d'autres. Personne ne peut être plus intelligent que la moyenne sur une île déserte.
Maintenant, on comprend pourquoi transférer cela à l'IA est si délicat. Quand quelqu'un calcule un g pour un ensemble de grands modèles de langage (LLMs), ce facteur est un artefact de l'ensemble qu'il a choisi. Nous mesurons une position dans un tableau, et nous la présentons comme si c'était une propriété interne du système.
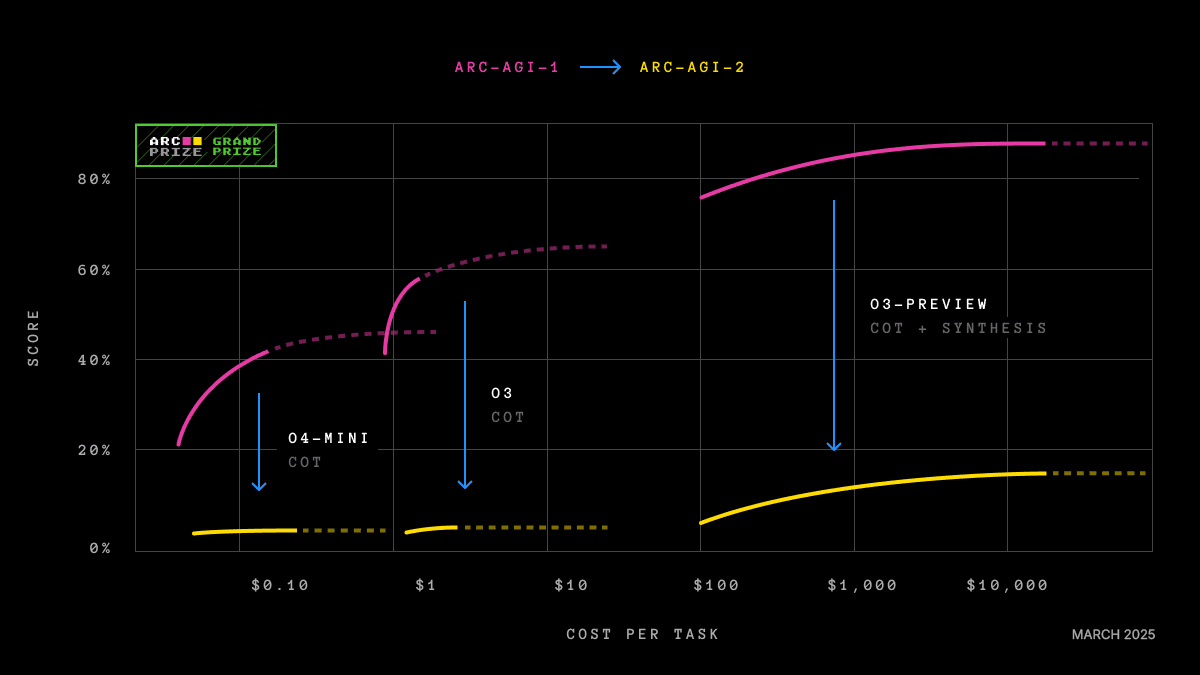
Appliquer le facteur g à l'intelligence artificielle : une tentation dangereuse
La tentation de transférer tout cela à l'IA était irrésistible. Gignac et Szodorai ont proposé que, si la performance des modèles sur des tâches variées est corrélée positivement, il devrait être possible d'identifier un facteur général de capacité dans les systèmes artificiels également. Et en effet, plusieurs travaux récents appliquent l'analyse factorielle à des batteries de tests dans les LLMs et trouvent un facteur g unidimensionnel qui reste stable à travers les modèles, les batteries et les méthodes d'extraction (Ilić, 2023). Cela ressemble à une confirmation. Il est sage d'être méfiant.
L'apparition d'un facteur de premier ordre dominant ne prouve pas qu'il existe une capacité générale analogue à celle des humains. Cela prouve que les scores de ces modèles covarient. Et ils covarient pour une raison très superficielle : ils partagent l'architecture, ils partagent le corpus d'entraînement, ils partagent les recettes d'optimisation. Un modèle large et bien entraîné fait tout mieux qu'un petit modèle mal entraîné, sur toutes les tâches à la fois. C'est suffisant pour fabriquer un beau manchon positif qui ne nous dit rien sur la généralité cognitive. Cela nous parle de l'échelle de calcul. ATTENTION : le facteur que nous extrayons peut simplement être un facteur de taille déguisé en intelligence.
Le cerveau, de plus, ne concentre pas l'intelligence dans un seul module. Une multitude de sous-systèmes spécialisés traitent en parallèle et, lorsque qu'une information remporte la compétition, elle devient globalement accessible au reste du système, qui peut alors la recombiner à de nouvelles fins (Baars, 1988 ; Dehaene & Changeux, 2011). Ce que nous appelons la généralité est la disponibilité globale : mettre une pièce apprise dans un contexte au service d'un problème dans un autre. Ce n'est pas un nombre scalaire stocké ; c'est un motif d'accès et d'intégration. C'est ce type d'architecture fonctionnelle que Neuraxon essaie d'imiter — des sous-systèmes modulaires avec des dynamiques en temps continu et une plasticité multi-temporelle, plutôt qu'un transformateur monolithique.
François Chollet et l'approche moderne : Mesurer ce que vous ne savez toujours pas faire
Contre l'héritage psychométrique, François Chollet a proposé en 2019 un tournant conceptuel. Son argument, dans Sur la mesure de l'intelligence, est que nous mesurions la mauvaise chose.
Les benchmarks d'IA traditionnels récompensent les compétences, des compétences spécifiques sur des tâches concrètes. Mais une compétence peut être achetée avec des données et des calculs : il suffit de s'entraîner suffisamment sur une tâche pour la maîtriser. L'intelligence, soutient Chollet, n'est pas une compétence, mais l'efficacité dans l'acquisition de compétences : combien vous apprenez avec peu, face à une tâche réellement nouvelle (Chollet, 2019).
L'intelligence est ce que vous faites quand vous ne savez pas quoi faire.
Cette distinction change tout. Un système qui résout un million de problèmes parce qu'il a vu dix millions de similaires n'est pas intelligent. Un système intelligent est celui qui, face à un problème pour lequel il ne pouvait pas se préparer, découvre la structure et s'adapte avec peu d'exemples. La mesure cesse d'être le résultat final et devient la pente de l'apprentissage.
ARC-AGI : Le benchmark qui teste le raisonnement véritable de l'IA
L'ARC-AGI est né de cette idée, et sa version la plus récente, l'ARC-AGI-3, va plus loin. Ce n'est pas un test de questions-réponses. C'est un ensemble d'environnements interactifs, comme des mini-vidéogames, dans lesquels l'agent explore un monde inconnu, déduit quel est l'objectif sans qu'on lui dise en langage naturel, construit un modèle de l'environnement et adapte sa stratégie étape par étape (ARC Prize, 2025).
Les principes de conception sont explicites : environnements 100 % solvables par des humains, sans connaissances préchargées ou instructions cachées, et avec suffisamment de nouveauté pour empêcher la mémorisation. Ce qui est noté, ce n'est pas le fait d'avoir raison, mais l'efficacité dans l'acquisition de compétences au fil du temps.
C'est l'opposé du facteur g : au lieu de chercher ce qu'un système maîtrise déjà et de le résumer, il cherche ce qu'il ne sait toujours pas faire et mesure combien cela lui coûte d'apprendre.
Contamination des données : Pourquoi les scores de benchmark des LLM sont gonflés
La raison ultime pour laquelle l'approche de Chollet est importante, et pourquoi le facteur g appliqué aux LLMs est si glissant, a un nom technique : contamination des données. Si l'examen, ou quelque chose d'aussi identique, était dans les notes que l'étudiant a étudiées, sa note ne mesure pas ce qu'il peut raisonner. Elle mesure ce qu'il a mémorisé.
Les modèles de langage sont entraînés sur des livres, des forums, des dépôts de code, des articles, pratiquement tout le texte disponible. Les benchmarks avec lesquels nous les évaluons sont publiés sur Internet. La conclusion est que des fragments des tests finissent dans les données d'entraînement, ce qui viole la séparation entre l'entraînement et l'évaluation et gonfle les scores (Xu et al., 2024; Deng et al., 2024). Des audits empiriques ont détecté des niveaux de contamination allant de 1 % à 45 % dans des benchmarks largement utilisés, et le problème s'aggrave avec le temps (Li et al., 2024).
Ce n'est pas un problème mineur de quelques questions fuitées. Dans des benchmarks comme MMLU ou GSM8K, une partie de ce que nous interprétons comme du raisonnement peut être de la pure mémorisation (Chen et al., 2025). Lorsque des techniques de décontamination sont appliquées, réécrivant les éléments fuités sans altérer leur difficulté, la précision chute : dans une étude, 22,9 % sur GSM8K et 19,0 % sur MMLU (Zhu et al., 2024).
Les éléments paraphrasés, ou même ceux traduits dans une autre langue, esquivent les détecteurs de chevauchement superficiels et continuent de gonfler les résultats (Yang et al., 2023 ; Yao et al., 2024). Les solutions habituelles (paraphrasage, traduction, ajustement du contexte) sont supposées être efficaces sans avoir été rigoureusement validées. Et pour la plupart des modèles ouverts, nous ne pouvons même pas vérifier quoi que ce soit, car leurs données d'entraînement ne sont pas publiées. Nous notons des examens sans savoir ce que l'étudiant a étudié.
Ici, on comprend pourquoi l'ARC-AGI a choisi le chemin qu'il a choisi. Un environnement interactif, nouveau, sans instructions en langage naturel et conçu pour empêcher la mémorisation par force brute est, par construction, résistant à la contamination.
Alors, que devrions-nous mesurer pour évaluer l'intelligence des machines ?
Le facteur g est une propriété populationnelle qui, appliquée à des modèles partageant l'architecture et le corpus, risque de mesurer l'échelle de calcul et non la généralité. La leçon pour quiconque construit des systèmes artificiels n'est pas de choisir entre le facteur g et l'ARC-AGI comme s'ils étaient des équipes rivales. C'est de comprendre quelle question chacun répond. Une analyse factorielle peut être utile pour décrire la structure interne de la performance d'un système, tant que le premier facteur n'est pas confondu avec une essence de l'intelligence. Et un protocole de type ARC est indispensable pour ce qui compte vraiment : vérifier si le système généralise au-delà de ce qu'il a vu, ou se contente de réciter.
Lorsque nous évaluons un système uniquement par sa réponse finale, nous le mesurons les yeux fermés à sa dimension temporelle : la planification, la mise à jour des croyances, l'intégration des preuves à travers de nombreuses étapes. C'est exactement ce que l'ARC-AGI-3 a décidé de noter, et exactement ce qu'un examen statique ne peut pas voir.

Pourquoi les architectures d'IA inspirées du cerveau comme Neuraxon prennent une voie différente
Si l'intelligence n'est pas un nombre stocké mais l'intégration efficace de sous-systèmes spécialisés, comme le suggère la théorie de l'intégration parieto-frontal (P-FIT) et la disponibilité globale de l'espace de travail dans le cerveau...
Si cette intégration est avant tout un phénomène temporel, avec des échelles de temps...
Alors un système construit sur des architectures modulaires avec des sphères fonctionnelles, une plasticité à travers plusieurs échelles temporelles et une dynamique continue n'a pas besoin d'être évalué en lui demandant de réciter des réponses.
La bonne question n'est pas combien de benchmarks il bat, mais avec quelle efficacité il acquiert de nouveaux comportements, au fil du temps, dans des environnements pour lesquels il n'était pas préparé. C'est la direction que Neuraxon essaie de prendre. Calculer le temps — c'est-à-dire l'adaptation — pas des réponses mémorisées qui simulent être un bon élève, alors qu'en réalité, il connaît déjà les questions.
Références
Chollet, F. (2019). Sur la mesure de l'intelligence. arXiv:1911.01547.
Deary, I. J., Penke, L., & Johnson, W. (2009). La neurosciences des différences d'intelligence humaine. Nature Reviews Neuroscience.
Dehaene, S., & Changeux, J.-P. (2011). Approches expérimentales et théoriques du traitement conscient. Neuron, 70(2), 200–227.
Detterman, D. K., & Daniel, M. H. (1989). Corrélations des tests mentaux entre eux et avec des variables cognitives. Intelligence.
Gignac, G. E., & Szodorai, E. T. (2024). Définir et identifier un facteur général de capacité dans les systèmes d'IA.
Guttman, L. (1955). La détermination des matrices de scores factoriels avec des implications pour cinq autres problèmes fondamentaux de la théorie des facteurs communs. British Journal of Statistical Psychology.
Hernández-Orallo, J., et al. (2021). L'intelligence générale démêlée via une métrique de généralité pour l'intelligence naturelle et artificielle. Scientific Reports.
Honey, C. J., et al. (2012). Dynamiques corticales lentes et accumulation d'informations sur de longues échelles temporelles. Neuron, 76(2), 423–434.
Ilić, D. (2023). Dévoiler le facteur d'intelligence générale dans les modèles de langage : Une approche psychométrique. arXiv:2310.11616.
Jung, R. E., & Haier, R. J. (2007). La théorie de l'intégration parieto-frontal (P-FIT) de l'intelligence. Behavioral and Brain Sciences.
Spearman, C. (1904). "L'intelligence générale" déterminée et mesurée objectivement. American Journal of Psychology, 15, 201–293.
Roberts, M., et al. (2024). Preuves temporelles de contamination à partir des dates de coupure d'entraînement.
Schönemann, P. H. (2008). Une réponse à Mackintosh et quelques remarques sur le concept d'intelligence générale. arXiv:0808.2343.
Xu, C., et al. (2024). Contamination des données de benchmark des grands modèles de langage : un aperçu.
Yang, S., et al. (2023). Repenser les benchmarks et la contamination pour les modèles de langage avec des échantillons reformulés.
Zhu, Q., et al. (2024). Décontamination en temps d'inférence : Réutilisation de benchmarks fuités pour l'évaluation des LLM. Résultats de l'EMNLP 2024.
ARC Prize (2025). ARC-AGI-3 : Un benchmark de raisonnement interactif. Rapport technique.
Explorez l'ensemble de la série de l'Académie d'Intelligence Neuraxon
Ceci est le Volume 10 de l'Académie d'Intelligence Neuraxon par l'équipe scientifique de Qubic. Si vous nous rejoignez, explorez l'ensemble de la série pour construire une compréhension complète de la science derrière Neuraxon, Aigarth et l'approche de Qubic en intelligence artificielle décentralisée inspirée du cerveau :
NIA Volume 1: Pourquoi l'intelligence n'est pas calculée par étapes, mais dans le temps — Explore pourquoi l'intelligence biologique opère en temps continu plutôt que par étapes de calcul discontinues comme les LLMs traditionnels.
NIA Volume 2: Dynamiques ternaires comme modèle de l'intelligence vivante — Explique les dynamiques ternaires et pourquoi la logique à trois états (excitatoire, neutre, inhibiteur) est importante pour modéliser les systèmes vivants.
NIA Volume 3: Neuromodulation et IA inspirée du cerveau — Couvre la neuromodulation et comment le signalement chimique du cerveau (dopamine, sérotonine, acétylcholine, noradrénaline) inspire l'architecture de Neuraxon.
NIA Volume 4: Réseaux de neurones en IA et neurosciences — Une comparaison approfondie des réseaux de neurones biologiques, des réseaux de neurones artificiels et de l'approche de troisième voie de Neuraxon.
NIA Volume 5: Astrocytes et IA inspirée du cerveau — Comment le contrôle astrocytaire transforme la plasticité du réseau de neurones à travers le cadre AGMP dans Neuraxon.
NIA Volume 6: Machines conscientes vs organismes intelligents : L'explication de la conscience de l'IA — Explore la conscience de l'IA à travers le prisme de la théorie de l'espace de travail global, de la théorie de l'information intégrée et du codage prédictif.
NIA Volume 7: Le jeu de la vie de Conway, la vie artificielle et les écosystèmes numériques — La science derrière Qubic, Aigarth et la complexité émergente de Neuraxon et la criticité auto-organisée.
NIA Volume 8: La criticité cérébrale et le rapport de ramification dans les réseaux neuronaux et artificiels — Pourquoi un rapport de ramification proche de 1 et la criticité auto-organisée sont des principes de conception bio-inspirés dans Neuraxon.
NIA Volume 9: Les origines du facteur g : De l'éducation et des neurosciences à l'intelligence artificielle — Explore les origines du facteur g à travers l'éducation, les neurosciences et l'IA.
$Qubic est un réseau décentralisé et open-source pour la technologie expérimentale. Pour en savoir plus, visitez qubic.org. Rejoignez la discussion sur X, Discord et Telegram.