晚上好,朋友们。我是阿祖,做预测市场最容易踩的坑,不是押错方向,而是被“信息流”牵着鼻子走。你会发现很多题目最后吵翻天,根本不是大家对结果判断不同,而是数据源本身被带节奏:有人用一张断章取义的截图、一个删改过的公告、甚至一段剪辑的直播片段,把市场情绪推到某个方向;更狠的是,有些“带节奏”不需要黑客攻击,只需要制造一段足够像真的叙事,然后等着 oracle 或结算方把它当事实写进链上。信息战时代,oracle 要防的不止黑客,还有叙事污染——因为预测市场从来不是“赌结果”,它早就升级成“赌事实怎么被定义、怎么被证明”,而你下注的本质,是在为某一套事实判定机制买单。
这就是为什么我反复说,多源共识和 AI 语义分析不是锦上添花,而是“防带节奏”的底层武器。你只要依赖单一来源,哪怕它看起来权威,也会存在时间差、口径差、甚至临时修订的风险;你只要只看“表面一致”,就会在极端时刻被假一致骗过。APRO 在 Binance Research 的介绍里把它的核心结构讲得很直白:Submitter Layer 的智能 oracle 节点会通过 多源共识 + AI 分析去验证数据,而 Verdict Layer 则用 LLM 驱动的 agents去处理提交之间的冲突,最后由链上结算合约聚合并交付给应用。 你把这套设计放到预测市场里看,就很像“先把信息分散地收上来,再用更强的语义脑子把冲突掰开揉碎”,把被带节奏的空间压到最小。

“带节奏”最常见的套路,其实就三类。第一类是时间差:早期快讯先冲出来,后面官方修订、补充条件、甚至撤回,但市场已经押完了;第二类是口径差:同一个事件,媒体标题写得很满,正文却有前提条件,或者只是引用匿名消息源;第三类是证据差:你看到的是二手转述或截图,而不是可追溯的原始文件。传统 oracle 只擅长把数字搬上链,但预测市场需要的是“把上下文搬上链”,而 APRO 在一些介绍里就强调 Verdict Layer 像网络的大脑,用语义分析理解上下文、解决数据冲突,比如区分短暂的市场噪声和更可信的趋势,并且把过程做成可追溯的链路(时间戳、签名、可验证)。 这句话翻成预测市场语言就是:它不只在问“这句话是真的吗”,它还在问“这句话在什么语境下成立、它和其他证据怎么对齐、冲突时该信谁”。

于是规则变化就很明确了:预测市场如果要扩张到更复杂事件,平台会越来越依赖 AI oracle,把“事实判定”做成基础设施,而不是靠人工仲裁撑规模。你会看到平台选题越来越像写合同:命题要可计算、来源要可核验、冲突要可处理。反过来,oracle 的竞争也会从“谁更快”变成“谁更能抗叙事污染”:能不能跨来源交叉验证,能不能识别断章取义,能不能在证据不完整时输出更保守的结论或触发更严格的复核流程。
对用户来说,这也解释了一个现实问题:为什么高质量数据要收费,而且往往不便宜。因为你买的不是“一个答案”,你买的是一整套降低争议成本的机制:多源采集是成本,交叉验证是成本,冲突裁决是成本,可追溯与可审计也是成本。你不愿意为数据付费,市场就会用另一种方式让你付费——用错误结算、争议拉扯、以及“被带节奏后再反转”的波动把成本收回来。换句话说,数据费本质上是在买“更低的被操纵概率”和“更可解释的结算结果”,这在预测市场这种强争议场景里,往往比你想象的更值钱。
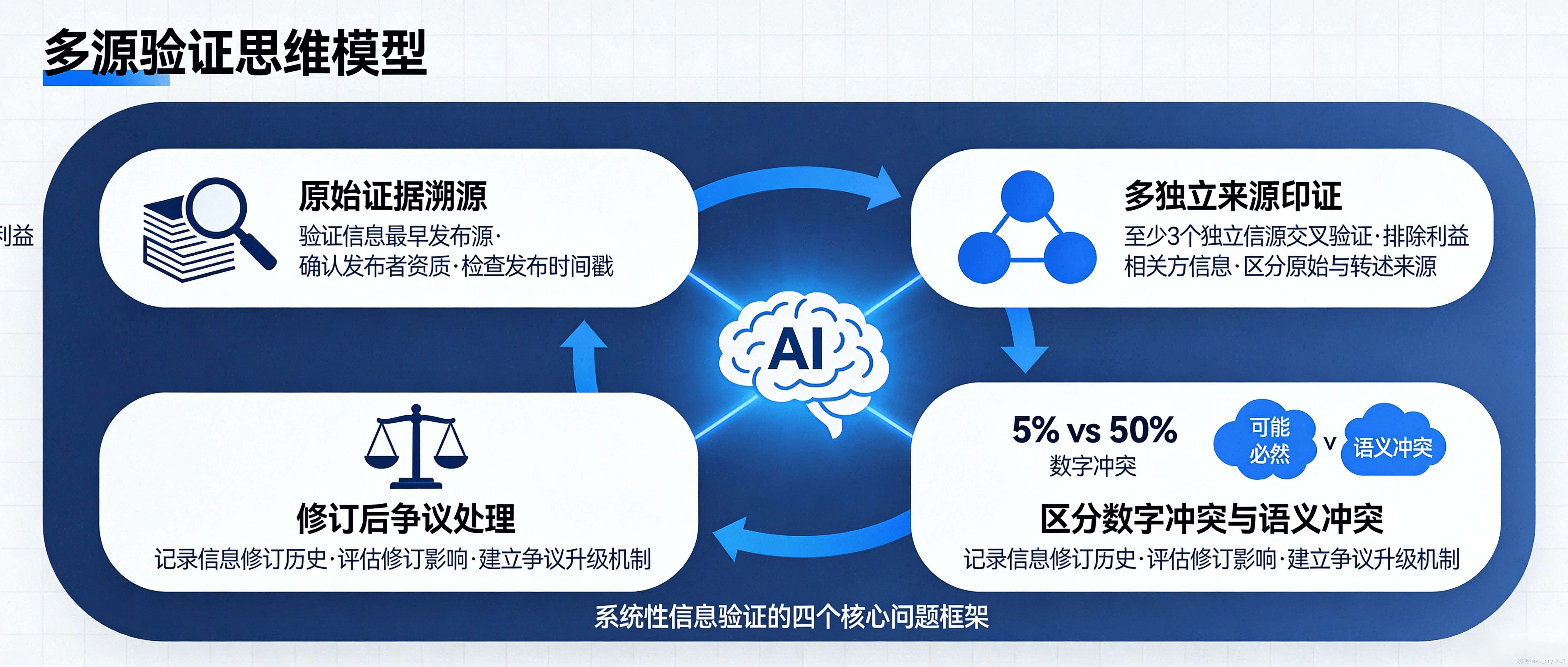
最后给你一个我自己用的“多源验证思维模型”,你可以直接拿去教读者做题、也可以当你后续内容的伏笔:当你看到一个热门预测题,先别急着站队,先在脑子里过四个问题——这条信息的“原始证据”是什么,能不能追溯到可核验的源头;除了这一个源头,是否存在至少两个独立来源能在关键事实点上互相印证;如果不同来源出现冲突,冲突发生在“数字层”(值是多少)还是“语义层”(算不算发生、条件是否满足),语义冲突往往比数字冲突更危险;最后再问一句最关键的:如果这条信息后来被修订/撤回,结算机制有没有能力识别版本差异并处理争议。你把这四个问题养成习惯,就会自然理解为什么“多源共识 + 语义裁决”是预测市场的护城河,也会更理解平台为什么需要像 APRO 这样把冲突处理放进网络核心的设计。

