I was grabbing a drink with a few old-school infra engineers last week, and the conversation inevitably soured into the absolute mess that is the current AI "trust" landscape. We’re currently living through this bizarre era where we’re basically treating LLMs like digital oracles—we ask a question, get a wall of text, and then just cross our fingers and hope the model didn't decide to hallucinate a legal precedent or a structural engineering flaw for the hell of it. The industry’s solution so far has been to throw more "vibe-based" evaluations at the problem, which is about as effective as trying to audit a bank by asking the teller if they feel like the numbers probably add up. We’ve been desperately needing a way to move past this blind faith, but the technical debt of verifying complex, generative output is a nightmare that most teams are just too terrified to touch.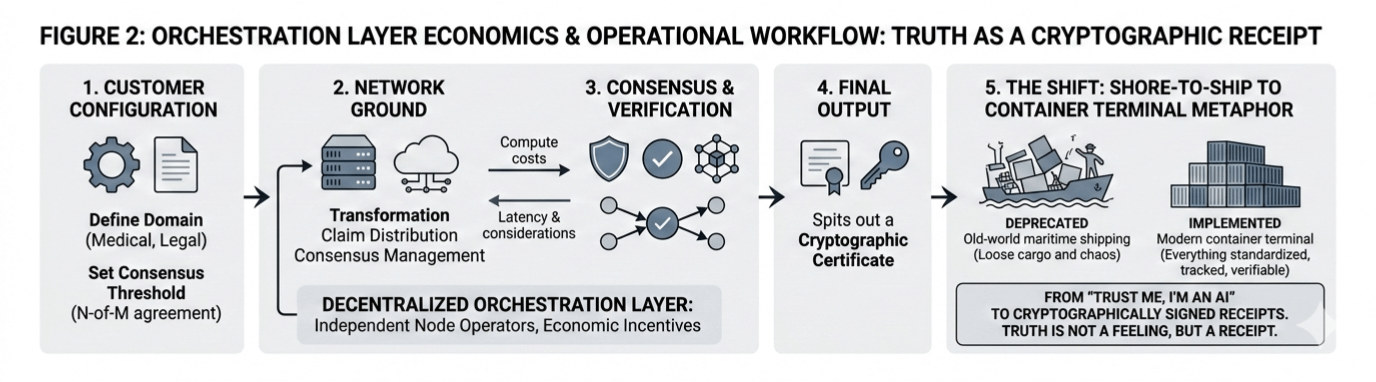
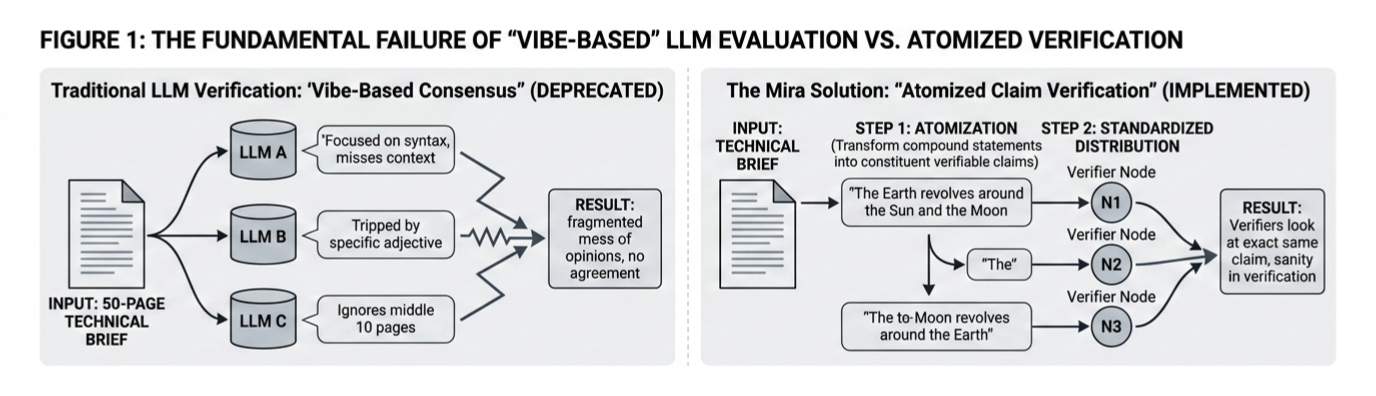
The fundamental rot in the old way of doing things is that you can't just hand a fifty-page technical brief to three different models and ask them if it’s "correct." It’s a total failure of logic; one model focuses on the syntax, another gets tripped up on a specific adjective, and a third just ignores the middle ten pages entirely. You end up with a fragmented mess of opinions that can’t reach a consensus because they aren't even looking at the same problem. This is where I think Mira is actually onto something that isn't just another Web3 buzzword. Instead of trying to verify a sprawling, messy narrative all at once, they’re essentially atomizing the content. They take a compound statement like the Earth revolving around the Sun and the Moon revolving around the Earth and strip it down into its constituent, verifiable claims. It’s the difference between trying to grade an entire essay in one go and checking every single fact against a primary source. By standardizing the output into these discrete units, every verifier node in the network is forced to look at the exact same claim with the exact same context, which finally brings some sanity to the verification process.
Of course, the "visionary" part of this only works if the "bone-deep reality" of the economics holds up. Mira is trying to build this decentralized orchestration layer where independent node operators are economically incentivized to be honest, which is a tall order when you consider the sheer latency and compute costs involved. You’ve got this systematic workflow where a customer sets their domain—say, medical or legal—and defines a consensus threshold, like an N-of-M agreement. The network then grinds through the transformation, claim distribution, and consensus management before spitting out a cryptographic certificate. It’s a heavy lift, and the cynical side of me wonders if the world is ready to pay the premium for that kind of rigor, but the alternative is a digital landscape where we literally can’t tell the difference between a hallucination and a hard fact. We’re moving toward a source-agnostic future where it doesn't matter if a human or a bot wrote the code; what matters is whether the claims hold water.
If we don't get this right, we’re essentially building a massive library where the books rewrite themselves every time you close the cover. Mira’s approach feels less like a simple "fact-checker" and more like a sophisticated sorting machine for the truth. It reminds me of the shift from old-world maritime shipping to the modern container terminal. Before, you had loose cargo and chaos; now, everything is standardized, tracked, and verifiable. We are finally moving away from the era of "trust me, I’m an AI" and toward a world where truth isn't a feeling, but a cryptographically signed receipt.