
我已經關注AI領域一段時間了,有一件事一直在我腦海中迴盪。
這些系統變得越智能,信任似乎就越重要。
不是那種相信AI能夠正確回答問題的信任。
我的意思是要相信信息最初來自哪裏。
幾年前,大多數人幾乎不考慮數據源。如果一個應用程序能夠正常工作,那就足夠了。現在感覺不一樣了。人們開始問更多的問題。他們對來源、問責制感到好奇,以及他們正在使用的系統是否真的可以驗證。
出於某種原因,這一轉變感覺比許多人意識到的要大。
我最近發現自己從那個角度思考@OpenLedger 。

吸引我注意的不是某個功能或技術更新,而是更廣泛的觀點,即未來的AI系統可能需要更強的信任基礎,才能成爲日常生活的一部分。
互聯網已經在許多看不見的方式上依賴信任。
我們信任交易。
我們信任網站。
我們信任平臺來處理信息。
但人工智能引入了另一層信任。現在我們還在信任那些從大量數據中學習的模型,通常不知道那些數據的來源。
這就是對話開始變得有趣的地方。
感覺數字信任正在慢慢成爲它自己的一層基礎設施。
不是人們直接看到的東西,而是悄悄支持着一切建立在其上的東西。
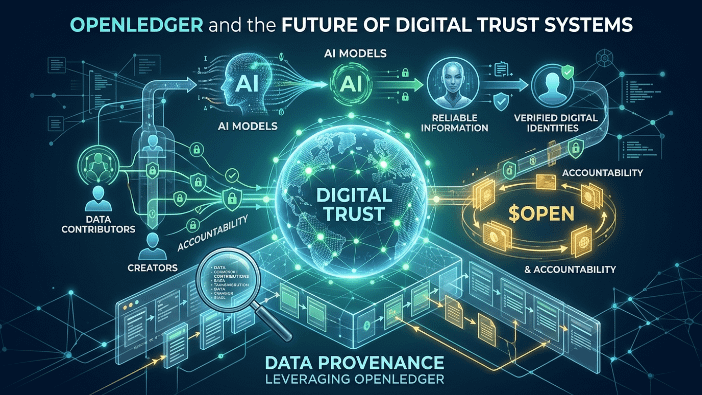
當我閱讀關於#OpenLedger 的討論時,我經常回到這個想法。該項目似乎與一個數據貢獻、模型開發和AI輸出可以更透明地鏈接的未來相關,而不是存在於封閉的牆後。
也許這就是這個想法一直留在我腦海中的原因。
一個系統的價值不僅僅在於它所產生的東西。
有時候,這就是人們能夠自信依賴它的方式。
隨着人工智能變得越來越普遍,信任可能會成爲整個生態系統中最有價值的資源之一。
不是關注。
不是速度。
信任。
這也讓我對$OPEN 有了不同的想法。
與其僅僅通過市場的視角來看待它,我發現自己在關注它在一個圍繞可驗證參與和問責制的網絡中可能扮演的角色。
當然,沒有哪個系統能解決所有問題。
技術通常不是這樣運作的。
不過,感覺探索數字信任的項目正在關注一個隨着時間的推移會變得越來越難以忽視的問題。
誰貢獻的?
信息來源於哪裏?
這個過程能被驗證嗎?
隨着人工智能的持續發展,這些問題似乎變得越來越相關。
也許只是我,但人工智能的未來似乎不再依賴於創建更大的系統,而是更依賴於創建人們真正可以信任的系統。
這個想法讓我不斷回到#openledger 和圍繞它的對話。
我們可能在接下來的幾年裏學習到這個區別究竟有多重要。
