老實說,通用智能挺有用的,但本地知識才是真正的價值所在。
聽起來有點平淡,但這很重要。
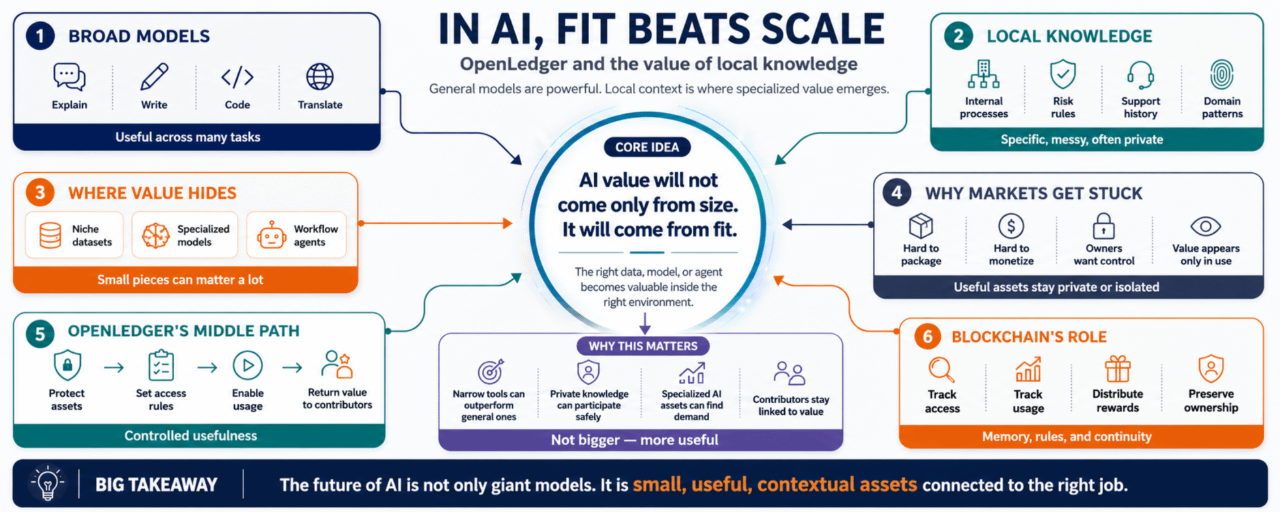
大型模型可以回答很多問題。它可以解釋、總結、寫作、翻譯、編碼,並在廣泛的主題上進行推理。這很令人印象深刻。但當工作變得具體時,模型往往需要其他東西。
它需要上下文。
不僅僅是任何上下文。
正確的上下文。
一個公司的內部流程。
一家醫院的病人流動。
一個交易者的風險規則。
一個支持團隊過去的工單。
一個物流網絡的小延遲。
一個法律團隊的文件模式。
一個開發團隊的代碼習慣。
這些往往不是開放互聯網能很好教會的東西。
它們是本地的。
具體的。
雜亂的。
通常是私密的。
這就是人工智能開始變得更有趣的地方。
因爲未來可能不僅僅是關於誰擁有最大的模型。它也可能與誰能將有用的模型連接到最相關的本地知識而不失去控制有關。
@OpenLedger 符合這種想法。
不是關於人工智能和區塊鏈的喧囂承諾。更像是一個系統試圖讓本地人工智能資產在更廣泛的市場中存在。
數據、模型和代理並不完全相同。但它們有一個共同點:當它們連接到正確的用例時,它們變得更有價值。
來自一家企業的數據集從外面看可能很無聊。
在一個狹窄任務上訓練的小模型可能看起來不重要。
爲一個工作流程構建的代理可能感覺不像一個大產品。$PORTAL
但在正確的環境中,這些東西可能非常重要。
通常可以通過觀察人工智能在實際工作中的表現來判斷這一點。通用的答案往往只是開始。有效的答案是在系統理解了環境之後得出的。人們使用的術語。他們採取的快捷方式。他們避免的風險。隨着時間的推移悄然重複的模式。
這種知識很難打包。
更難以貨幣化。
如果一家公司擁有有用的本地數據,它可能不想出售。如果一個開發者有一個針對某一行業調優的模型,他們可能不想讓其被吸收入更大的平臺。如果一個代理在特定工作流程中表現良好,其價值可能直到有人實際使用它時纔會顯現。
所以市場陷入了僵局。
有用的知識保持私密。
有用的模型保持孤立。
有用的代理保持小巧。
#OpenLedger 似乎在試圖爲此創造一條中間道路。
一種使人工智能資產可用而又不完全脫離其源頭的方式。讓本地知識在規則下流動的方式。如果這種知識幫助某人構建有用的東西,價值可以迴流的方式。
這是一個微妙的想法。
這與讓一切開放並不相同。一些知識不應該開放。一些數據需要限制。一些代理只能在特定條件下運行。
但封閉的知識也有一個問題。如果它從未與任何東西連接,它的價值就會被困住。
所以,也許真正的問題不是開放與封閉。
而是受控的有用性。
一個資產能否保持保護並仍然參與?
一個模型能否專業化並仍然找到需求?
一個代理能否狹窄並仍然從實際工作中獲利?
本地知識能否在不被完全吞沒的情況下成爲人工智能的一部分?
這就是區塊鏈可以發揮作用的地方,如果謹慎使用。
一個賬本可以幫助追蹤訪問、使用和獎勵。它可以給人工智能資產一些連續性。它可以使貢獻者和用戶之間的關係不那麼依賴於私人信任。當然,這不完美。但也許足以使新的共享方式成爲可能。$PLAY
這很重要,因爲人工智能變得越來越具有上下文。
廣泛的模型只是一個層次。在其周圍,將會有更小的數據集、私密的記憶、專業的模型、工作流程和理解某個領域比通用系統更好的代理。
這並不使它們變得更大。
這使它們變得有用。
這是一個區別。
一個能很好處理一個業務流程的小代理可能比一個半途而廢的通用工具創造更多的實際價值。來自小衆領域的數據集在任務狹窄時可能比一個巨型公共數據集更重要。爲一個工作流程訓練的模型可能會因爲減少該領域的錯誤而變得有價值。#StrategyHintsNewBTCBuy
過一段時間後,很明顯人工智能的價值不僅僅來自規模。
它將來自於適配。
OpenLedger對數據、模型和代理的關注似乎圍繞着這種轉變。它爲使人工智能適應特定環境的組件提供了一個框架。這些組件需要所有權、訪問規則以及一些貨幣化的路徑。
沒有這些,本地知識將被鎖定,或者被更大的平臺吸收,而沒有太多的可見性。
這兩種結果都感覺不完整。
更平衡的路徑更難。這意味着允許有用的人工智能資產移動,但帶有記憶。帶有規則。讓貢獻者以某種方式保持與他們幫助創造的價值的連接。
OpenLedger正在嘗試在這個空間中工作。
而不是圍繞人工智能的最大喧囂版本。
而是圍繞更安靜的版本。
在這個版本中,一小部分知識,在正確的地方,可能比一個試圖瞭解一切的非常大型模型更重要。
@OpenLedger #OpenLedger $OPEN
文章
隨着AI的不斷髮展,有一件事變得越來越明確。