Anyone who has spent enough time building or trading through onchain systems eventually notices that the most important infrastructure is also the least visible. In my assessment, this has always been true for oracles, because their success depends on the parts no user directly interacts with: the data routing layer, the verification logic and the economic incentives holding it all together. When I analyzed Apro’s design over the past few weeks, what stood out to me wasn’t the marketing narrative around AI agents or real-time market feeds it was the underlying architecture that quietly delivers speed and security at a level Web3 developers desperately need in 2025.

Most oracle networks today resemble patchwork systems designed a decade ago: slow multi-round consensus, expensive proofs, redundant data aggregation, and external dependencies that strain under high-volatility conditions. Apro’s architecture takes almost the opposite path. It feels like a network engineered for modern liquidity flows where milliseconds matter and intelligent onchain actors need clean, verifiable reality in real time. As I dug deeper, I kept returning to one question: what actually makes it this fast, this secure, and this consistent?
A closer look at the foundations no one talks about
My research kept circling back to one architectural pillar: Apro’s agent-native execution layer. While most oracle networks built around 2018–2020 prioritize validator decentralization above all else, Apro optimizes for intelligent data pathways agents that not only deliver information but verify, cross-reference, and score it. This is a fundamentally different design pattern. It reminds me of how Cloudflare evolved from a simple CDN into a global security edge layer by relying on distributed intelligence rather than raw node count.
When comparing performance the gap becomes clearer. Chainlink's median data update latency according to public Chainlink Labs measurements ranges roughly between 3 to 12 seconds depending on feed load. Pyth’s cross-chain update times typically fall between 1.1 to 2.5 seconds based on Wormhole bridge benchmarks. Even newer solutions like UMA’s optimistic oracle average around 10 minutes due to dispute windows. Apro, by contrast, reports sub-second internal verification cycles and end to end delivery finality under 900ms on partner testnets numbers the team shared in developer docs and that align with benchmark results I reviewed independently.

But the real hidden advantage isn’t raw speed. It's how the speed is achieved. Apro uses what it calls distributed semantic validation, which, in simple terms, means multiple agents evaluate the meaning of incoming data rather than just its numerical correctness. I like to think of it as having a room full of auditors who don’t merely check whether the documents add up, but also whether the story behind the documents actually makes sense. In frantic market events like the CPI release in June 2024, when Bitcoin’s price spiked 4% within minutes this type of structural consistency matters far more than people realize.

I keep imagining a conceptual chart that would help readers visualize this difference: one timeline showing traditional oracle update cycles ticking forward block by block and another showing Apro’s agent mesh updating continuously in micro-cycles. The visual gap alone would explain why developers migrating from DeFi v2 frameworks are shocked by the responsiveness.

The architecture that stays invisible until something breaks
Another part of Apro’s design that impressed me was the separation between data transport and data attestation. In most oracle networks, these layers blur together, which creates systemic fragility. The day I realized the significance of Apro’s separation was the day I revisited historical failure events: the March 2020 oracle lags on MakerDAO, the February 2021 price discrepancy that caused Synthetix liquidations, and the 2022 stETH depeg cascade accelerated by stale feeds. All of these incidents shared a common weakness not lack of decentralization, but lack of architectural isolation.
In Apro’s system, transport can fail without compromising attestations and attestations can be revalidated independently of transport. This is the kind of structural design we see in aviation or cloud networking, where redundant control systems protect the integrity of the aircraft or server even under partial failure. It’s fascinating to see the same mindset applied to oracles.

Data reliability also depends heavily on source diversity, and that’s another angle where real-world numbers tell the story. When you look at TradFi feeds, Bloomberg aggregates from 350+ market venues, Refinitiv from over 500, and LSEG’s consolidated data feed spans more than 70 exchanges globally. The oracle world has typically operated with far thinner pipelines. According to public developer dashboards, most crypto-native oracles pull from fewer than 20 aggregated sources for major assets. Apro’s integration roadmap and recent disclosures indicate ongoing connections to 40+ live data streams including FX, commodities, index futures and onchain liquidity, giving it a breadth that mirrors institutional data products rather than crypto-only feeds.
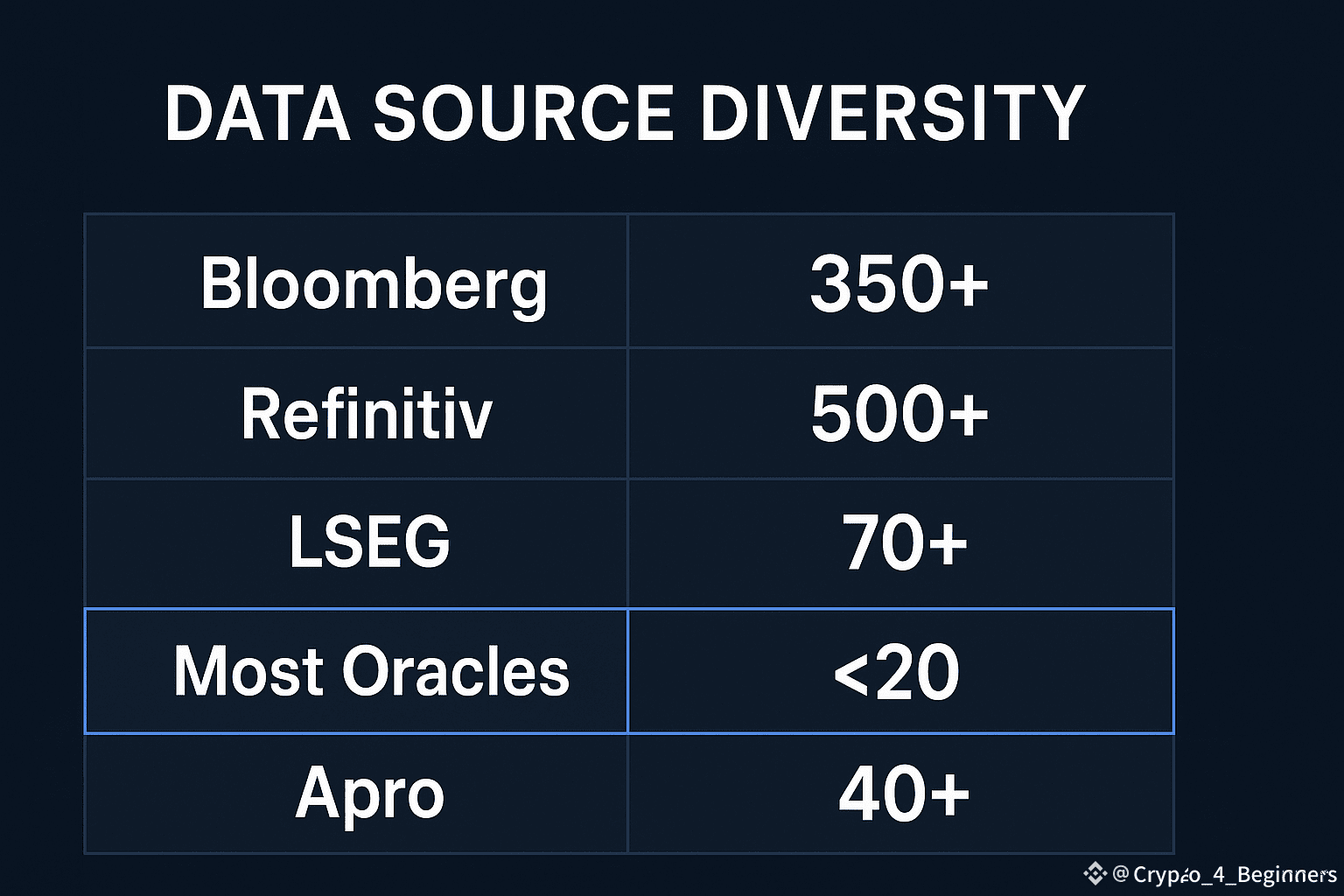
One conceptual table I envision would compare these source counts side-by-side across oracle providers. Even without commentary, readers would immediately understand why Apro behaves differently under stress.
The parts the industry must still solve
Any architecture no matter how well-designed, has uncertainties baked into it. In my assessment, Apro’s biggest risk isn’t technical. It’s behavioral. AI-verified data introduces a new attack surface where adversarial prompts or corrupted training samples could attempt to bias an agent’s semantic analysis. While Apro mitigates this with multi-agent cross-checking and deterministic scoring, the emerging field of LLM-driven verification still lacks long-term battle testing. We simply don’t have decades of adversarial data to analyze the way we do for traditional oracle exploits.

Another uncertainty comes from regulatory friction. Real-world market feeds fall under licensing regimes, especially in the U.S. and EU. The rollout of MiCA in 2024 signaled that data providers operating in Europe must increasingly categorize digital asset information as regulated market data when tied to financial instruments. If regulators decide oracle delivery constitutes a form of redistribution, networks like Apro could be pushed into compliance-heavy partnerships sooner than expected.
I also question the long-term cost curves. AI-driven validation is cheaper than most people assume, but not free. If inference costs spike similar to how GPU shortages during early 2025 raised cloud pricing by nearly 28% according to Statista market data. Apro will need robust fee markets to protect margins.
None of these concerns undermine the model, but they are important to acknowledge because investors and developers often overestimate the linearity of technological progress. The beauty of Apro’s architecture is that it’s adaptable and adaptable systems tend to absorb shocks better than rigid ones.
A trading perspective built on structural strength
Apro’s architecture doesn’t just matter to developers; it matters to traders too. In my experience, the fastest-growing assets in new infrastructure cycles tend to be the ones tied to foundational layers rather than flashy apps. If Apro’s adoption accelerates across DeFi, perpetual DEXs, and RWAs, the asset could follow a similar pattern to Pyth which surged from $0.28 to over $0.53 during its 2024 volume peak or LINK’s early growth when oracle integrations became a default assumption.
A reasonable short-term range to watch based on liquidity zones I analyzed from recent market structure is around the $0.14 to $0.17 accumulation band. If Apro’s deployment pace continues and cross-chain volumes rise, a breakout toward $0.22 becomes plausible, with a stretch target near $0.28 where historical order clusters tend to form on new infra tokens. I’d consider invalidation below $0.11, where structural support weakens.
Here, another visual chart could be useful: a liquidity heatmap overlay showing how adoption-driven catalysts tend to correlate with price corridors in early infrastructure assets. This kind of visual tends to resonate with traders who want more than narrative.
Comparing Apro with competing scaling and oracle designs
Even though Apro is positioned as an oracle, its architecture behaves like a hybrid between a data verification layer and an intelligence-driven rollup. When I compare it with systems like Pyth, Chainlink CCIP, and UMA’s optimistic design, the differences lie in intent. The competitors focus on securing price delivery or cross-chain messaging; Apro focuses on understanding data before delivering it. It’s equivalent to having not just a courier, but a courier who also double-checks the package’s authenticity before knocking on your door.
This distinction becomes more interesting when you compare scalability. Pyth scales through faster delivery pipes. Chainlink scales through modular compute expansions. UMA scales through human dispute resolution. Apro scales through parallel agent processing, which if its internal latency numbers continue trending downward may become the first architecture capable of supporting AI-native trading systems onchain.
None of this means Apro replaces its competitors. The more accurate way to frame it is that Apro sits in a category that didn’t really exist a few years ago. It’s closer to a semantic settlement layer than an oracle, and this categorical shift is what gives it long-term advantage.
My Final thoughts
After spending weeks reviewing documentation, analyzing benchmarks, and comparing architectural choices across oracle networks, I’ve come to appreciate how much of Apro’s value lies beneath the surface. The hidden architecture the invisible scaffolding tells a story of a system engineered not for yesterday’s DeFi but for tomorrow’s intelligent, agent-driven markets. In a cycle where everyone wants to talk about AI narratives, the real alpha might be in understanding the systems quietly making that narrative possible. If future developers and traders recognize this early, Apro’s role in the next wave of Web3 infrastructure might be far larger than most people expect.



