In the world of public chains, all transactions are written on the chain, which is both the most fascinating and the most unsettling aspect.
When you want to use artificial intelligence to help you with some sensitive analysis—such as organizing personal wallet transactions for tax planning, or letting the model check your years of trading records, do you really dare to throw this private data directly to a public contract?
That's almost like displaying bank transactions on a public screen, allowing anyone to see when you bought high or missed out.
Many truly valuable artificial intelligence scenarios have died on this point:
You either give up privacy or give up intelligence.
Kite's Service Layer has a role to play here. You can think of it as a whole layer of 'privacy computing black box':
Data is encrypted before entering, decrypted only after entering the box and participating in calculations, and once calculated, only the result and a verifiable mathematical proof are output; the raw data will not be on-chain from start to finish and will not be exposed to any third party.
Next, we will open the door of this 'black box' little by little from the perspectives of architecture, practical operation, and common pitfalls.
First, from 'data running naked' to 'secret room surgery'
The typical process of traditional on-chain calls is:
Wallet signing, transaction broadcasting, parameters written on the chain.
This is friendly for transfers and calling ordinary contracts, but it is almost a disaster for privacy scenarios.
Kite's Service Layer has divided this process into two worlds:
Off-chain secret room
Composed of Service Nodes, each node runs a trusted execution environment TEE internally.
Sensitive data is only decrypted and computed here; the outside world cannot see what happens inside.
On-chain settlement layer
Only receives summaries, hashes, and corresponding proofs of the calculation results,
Smart contracts are only responsible for verifying 'whether this calculation was performed according to the rules', without touching any raw data.
In simple terms, you no longer expose your body to the spotlight for examination, but enter a closed consultation room only visible to the doctor, where the outside only sees the words 'examination qualified'.
Second, architecture disassembly: A complete journey of sensitive data in the Service Layer
First, look at the data flow path in the system, then understand each step more clearly.
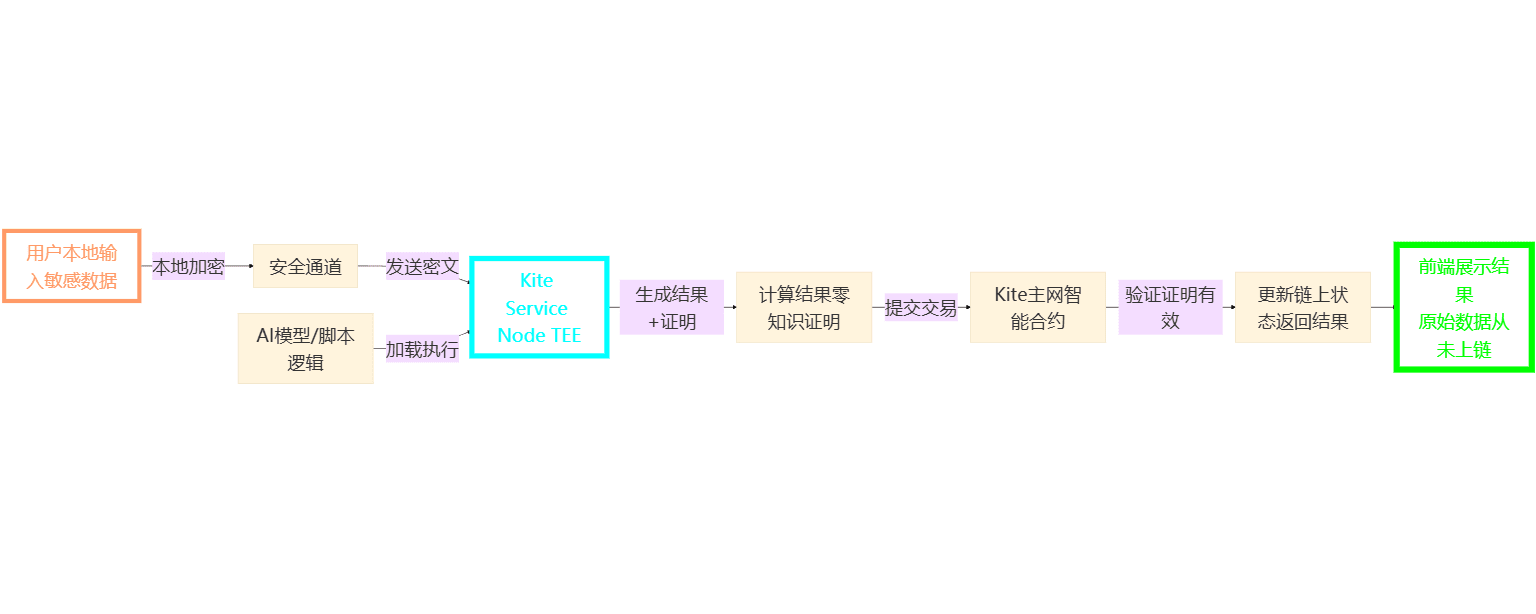
There are three key features.
First, end-to-end encryption of transmission
What you submit to the Service Layer is not plaintext, but encrypted input.
Even if intercepted midway, onlookers see a string of meaningless random numbers.
Second, the computation occurs within the 'black box'
The TEE of the Service Node is like a sealed cabinet:
Node operators can see how long the process has run but cannot see your data content.
Third, the result is verifiable
Service Node does not just return a 'judgment result', but will also attach a zero-knowledge proof.
On-chain contracts only need to verify whether the proof passes to confirm 'the calculation indeed ran according to the agreed logic'.
In this way, the caller does not need to trust the character of the node operator; they only need to trust the cryptography itself.
Third, practical exercise: Write a privacy-check service for 'whether assets meet the standard'
To align with CreatorPad's requirements for 'professionalism' and 'practicality', we use a very common scenario as an example:
Users wish to prove to a certain protocol that 'their assets exceed a certain threshold',
but do not want to disclose the specific balance to anyone.
The idea is:
Sensitive balances are only decrypted and used within the TEE,
the chain only sees 'meets standard' and a proof.
Step one: Write off-chain computation logic
Below is a minimalist asset-checking script, running in an internal TEE environment:
def main(private_balance: int, threshold: int):
if private_balance >= threshold:
return {
"status": "Qualified",
"flag": True
}
return {
"status": "Not Qualified",
"flag": False
}
There are two key points here.
First, the script itself does not care about data sources
It only processes function parameters and does not directly read any on-chain state, making it convenient for reuse in different businesses.
Second, the output intentionally performs 'minimum disclosure'
Only answer whether the threshold has been met, without returning specific amounts, to avoid leaking additional privacy.
Step two: Submit tasks through the Service Layer
Application server or local client calls tasks through Kite's Service SDK.
import { ServiceClient } from "@kite-ai/service-sdk";
const client = new ServiceClient("https://service-node.kite.network");
async function checkSolvency() {
const result = await client.submitTask({
script: "check_solvency.py",
inputs: {
private_balance: 50000,
threshold: 10000
},
privacy: "strict"
});
console.log(result.output);
console.log(result.proof);
}
In this step, it is worth noting that:
First, the input will be encrypted locally
What is actually sent to the network is the encrypted ciphertext,
Only TEE nodes with legal hardware environments can decrypt.
Second, the result contains two layers of information
The business result itself, for example, 'Qualified'
The corresponding cryptographic proof, used for subsequent on-chain verification.
Step three: Verify only the proof in the contract, do not touch privacy
On-chain, you can implement a contract interface similar to 'qualified investor marking', which only accepts results and proofs.
The pseudocode form is roughly as follows:
function verifyAndMark(
address user,
bytes calldata resultData,
bytes calldata proof
) external {
bool valid = KiteVerifier.verifyProof(resultData, proof);
require(valid, "invalid proof");
Verified[user] = true;
}
Contracts have no opportunity to touch the user's real balance from start to finish,
but can fully trust the conclusion of this check.
This is precisely the value of the Service Layer:
Moving sensitive computation from the on-chain environment to the privacy black box,
while retaining the most important feature of a decentralized world—verifiability.
Fourth, common pitfalls: The two places where privacy systems are most easily misused
As long as it involves privacy, there will always be pitfalls. Based on practical engineering experience, at least two points need special vigilance.
First, the cognitive inertia of 'on-chain plaintext parameters'
Some developers, when integrating the Service Layer, still habitually write all parameters into the input data of the on-chain transaction and let the nodes read them.
Once you do this, no matter how good the TEE and proof mechanisms are, they won't save you, because privacy has already been leaked before reaching the Service Node.
The correct approach is:
Use the encryption interface provided by Kite to encrypt sensitive fields locally,
Only hand over the encrypted payload to the Service Layer, avoiding any raw input appearing on-chain.
Second, 'unreasonable performance expectations'
Privacy computing is often heavier than ordinary requests,
especially for tasks that require generating zero-knowledge proofs, where time and computational overhead will significantly increase.
In system design, it is necessary to reserve in advance:
Appropriate timeout and retry mechanisms to avoid misjudging task failure due to network fluctuations
Distinguish between synchronous calls and asynchronous callbacks based on business importance; do not block all requests on the front-end page waiting for results
These details are not glamorous but directly determine whether a privacy system can run stably under real traffic.
Five, application imagination: From 'asset proof' to 'privacy identity'
Once you understand this model thoroughly, you will find that there is much more that can be done than just 'checking whether assets meet the standard'.
For example:
Only input the year of birth, determine whether of age in TEE, only record 'yes' or 'no' on-chain, without recording specific age
Connect with off-chain medical institutions, make a judgment on health indicators in the black box, only synchronize 'whether healthy meets the standard', rather than all medical data
Connect with transaction records, assess risk preferences in the black box, and let the protocol allocate appropriate leverage positions without disclosing your entire historical behavior
These are different scenarios of the same architecture.
Kite Service Layer not only adds a block of computing power to artificial intelligence but also provides a secure usage of private data.
Six, summary: In a transparent world, reserve a lockable room for data
The biggest advantage of public chains is transparency, verifiability, and auditability.
But real financial and identity scenarios are always inseparable from 'moderate privacy'.
Kite's Service Layer built this set of service layers, allowing two seemingly opposing things to coexist:
Sensitive data no longer runs naked, always kept in a verifiable black box
Business logic remains publicly transparent, and anyone can verify 'whether the rules have been correctly executed'
Who can combine artificial intelligence and on-chain finance without sacrificing privacy,
will hold the discourse power of the next stage of application layer ecology.
If you are already writing content related to the integration of artificial intelligence and Web3, you might as well practice once the development process of the Service Layer.
Even if it's just to create a minimalist service for 'whether it meets the standard', it is enough for you to understand emotionally:
What does 'the process can be hidden, but the result must be honest' mean?

I am a person seeking a sword from the boat, an analyst who only looks at essence and does not chase noise. @KITE AI $KITE #KITE



