
Main Takeaways
As automated abuse and bots became faster and more complex, Binance’s existing real-time protection systems started to strain under the weight of thousands of separate checks (individual automated rules or analyses that look for suspicious behavior) running in parallel.
To fix this, Binance built a smart Job Merging system that finds overlapping checks and combines them into fewer, more powerful workflows without changing what the checks actually do.
This upgrade cut computing resources by about 78% while keeping protection just as accurate and fast, saving significant costs and making the platform more efficient and scalable.

The rapid advancement of artificial intelligence (AI) and Web3 ecosystems have resulted in a new class of automated, abnormal high-frequency behaviours across trading and financial platforms. Some manipulative users have been trying to exploit the system by using AI-generated automation scripts to perform mass account registrations, farm rewards, and move funds – often within seconds.
Such fast and complex activities make it harder for platforms to manage risk in real time. Systems need to detect, decide, and act almost instantly, which can be a major challenge. This is where Binance’s in-house solution, Job Merging framework for optimizing real-time feature pipelines, comes in, helping us handle these high-speed operations more efficiently and reliably.
The Standard Abnormal Behaviour Detection Pipeline
The diagram below illustrates a typical pipeline used by many platforms to detect abnormal behaviour in real time. The system transforms operational events into low-latency features through four sequential stages: Change Data Capture (CDC), Data Cleaning, Feature Calculation, and Feature Serving. Each stage is responsible for capturing, transforming, computing, and delivering feature values that are used for real-time risk detection.
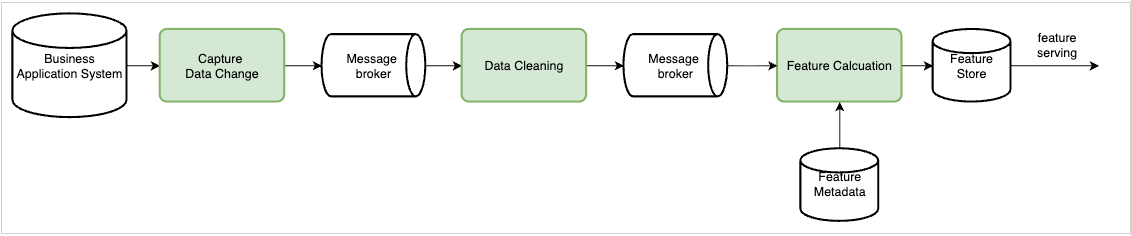
In our production environment, we leverage Apache Flink for both data cleaning and feature computation that can ensure millisecond-level freshness and consistency across distributed pipelines.
The Problem
As our platform rapidly grows, it generates thousands of independent feature calculation jobs, each catering to different feature requirements. This fragmentation can cause redundant data access and high resource consumption. To tackle this scalability challenge, we developed a job-merging framework that automatically consolidates compatible feature calculation jobs, reducing computational costs while maintaining low latency and accurate results.
The New System Architecture of Job Merging
The new workflow introduces a scalable, automated approach to consolidating feature-calculation jobs without compromising data accuracy or system stability. It begins by identifying compatible jobs through metadata-driven analysis, then applies rule-based filtering to select suitable merge candidates. Finally, a stability-aware deployment process ensures that any changes are rolled out safely and can be rolled back if needed.
With this architecture, large-scale job merging becomes more systematic and reliable, significantly reducing redundant computations and improving efficiency across real-time feature pipelines. In this section, we’ll deep dive into the specifics of this new workflow.
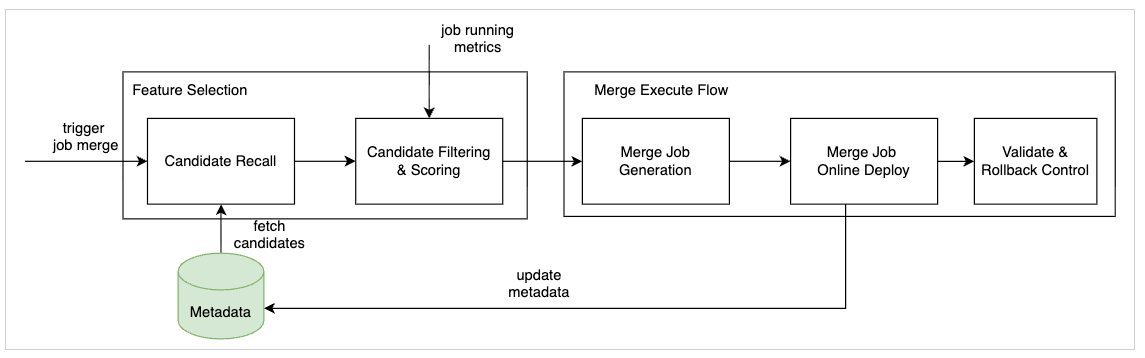
1. Candidate Selection
The process is initiated by a job-merge trigger, which can be invoked through an API or a scheduled process. The system first selects a seed feature job and retrieves a pool of candidate jobs from the metadata repository using a coarse recall strategy.
The selection is guided by the following metadata attributes:
Feature data source identify
Feature status (active/inactive)
Feature type (batch or streaming)
Feature storage format (e.g., single value, ring buffer, bitmap).
2. Candidate Filtering and Scoring
In the second stage, detailed candidate evaluation is performed to identify compatible feature jobs for merging. The filtering process considers both static metadata and runtime metrics to compute a compatibility score, based on:
The operator type used for computation (e.g., sum, count, last, first, min, count distinct)
The feature time window and refresh frequency
The actual runtime traffic volume of the feature job.
Only the top-ranked candidates are retained for merging, subject to a configurable threshold (typically ≤ 5 features per merge batch).
3. Merge Job Generation
Once the candidate set is finalized, the system generates a single optimized Flink job that consolidates the processing logic of all selected features. This step automatically:
Detects the required source columns from the metadata
Generates reusable processing logic and shared Flink operators
Produces a unified execution plan for writing merged feature outputs to the designated storage.
4. Merge Job Online Deployment
The merged job is then submitted to the Flink cluster for dual-running – where the new merged job runs concurrently with the original jobs to avoid any disruption of online feature serving. During this phase, the framework automatically performs cross-validation between old and new pipelines by routing a fraction of real-time requests to the new merged feature path. A monitoring dashboard continuously reports feature-value differences and validation metrics to ensure correctness before full activation.
5. Validation and Rollback Mechanism
To ensure correctness and robustness, the framework includes a data-validation module built on Hive SQL. This module retrieves validation keys from the data warehouse and checks that feature values generated by the merged job remain consistent with historical outputs.
To maintain zero-tolerance accuracy during deployment, we also introduced a grayscale release mechanism that routes only a controlled portion of traffic to the newly merged job. If discrepancies are detected, the system can immediately roll back to the original jobs, ensuring stability and reliability throughout deployment.
Outcome
All experiments were conducted using an Apache Flink cluster deployed on the production platform, with monitoring and validation tools integrated into our internal observability dashboard. The results are summarized below.
Resource Reduction and Efficiency
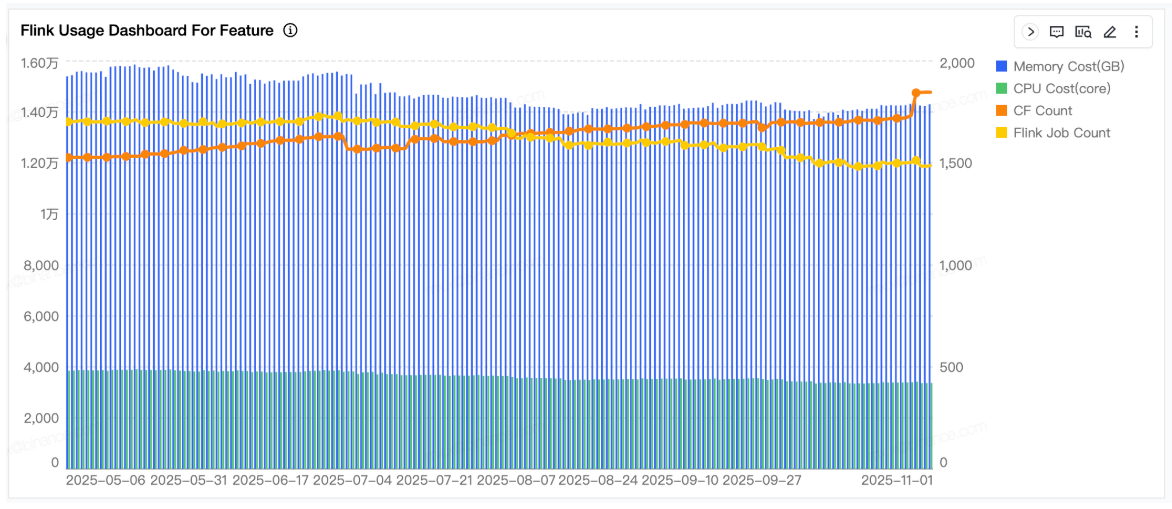
The table below shows a significant improvement with the number of active Flink jobs falling from 764 to 168, representing a 78% reduction in total operational workload. Similarly, resource usage fell by 78%.

Figure 4 shows substantial infrastructure savings, with CPU usage reduced from 1,528 to 336 cores and memory consumption dropping from 4,584 GB to 1,344 GB – an average reduction of 78%. This amounts to approximately 1,192 fewer CPU cores and 3,240 GB of memory being consumed across the cluster, translating to an estimated AWS cost saving of more than $20,000 per month.
Feature accuracy and stability
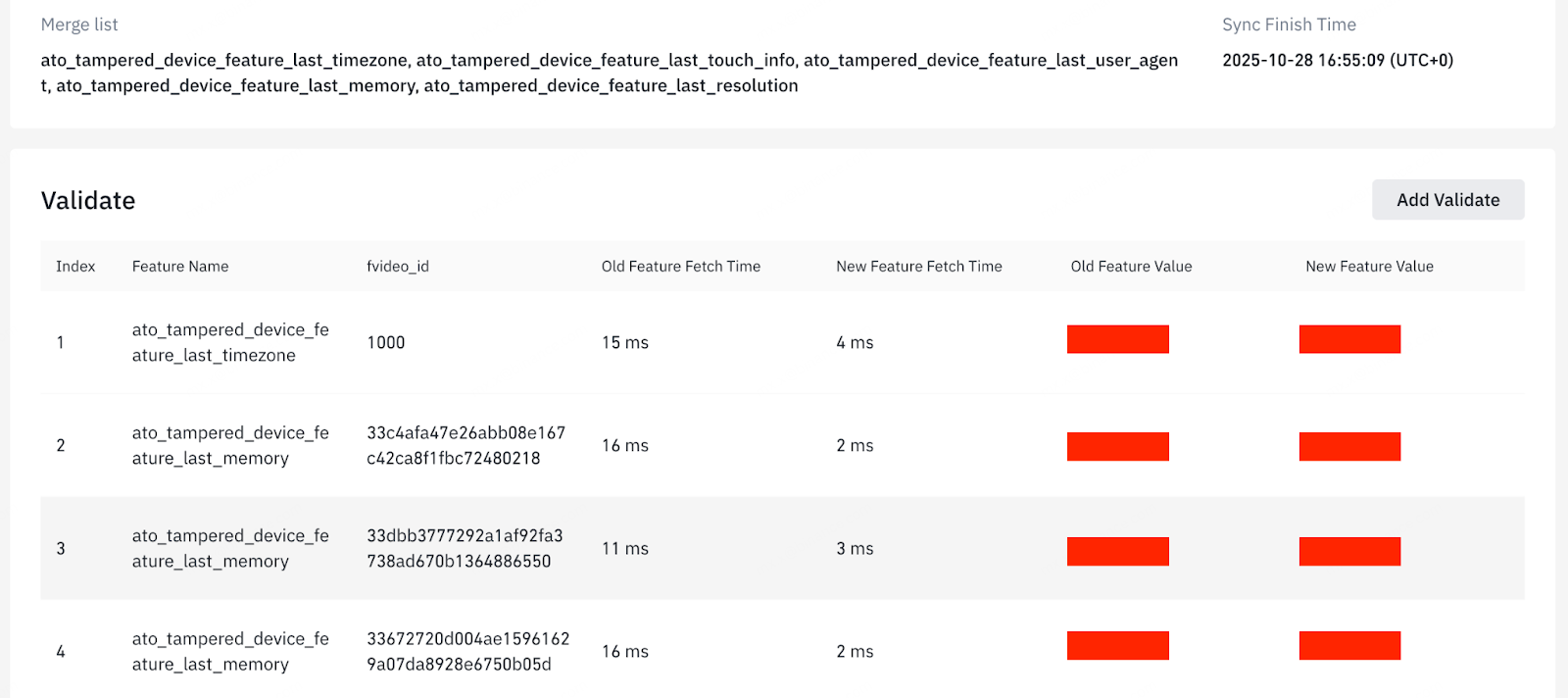
To ensure correctness, each merged job undergoes dual-run validation against its original source jobs before being fully activated. The validation framework compares feature outputs across both live traffic and offline datasets, confirming that values remain consistent in every environment. We only move to the next stage once the merged job achieves 100% feature equivalence with the original pipelines across all test samples. Figure 5 shows a selection of validation results generated using offline datasets.
Overall, the evaluation demonstrates that the proposed framework achieves substantial resource savings (78%), guaranteed feature-value consistency (100%), and stable latency performance (<15 ms P99) in real-world production scenarios.
Final Thoughts
At Binance, we continually strive for operational innovation at scale. The Job Merge project addresses the inefficiencies caused by thousands of redundant feature-calculation jobs in large production environments. By introducing automated candidate selection, rule-based similarity scoring, dual-run deployment, and comprehensive online-offline validation, the framework consolidates feature jobs while preserving correctness and latency stability. Production evaluation showed substantial gains, including up to 78% reductions in CPU and memory usage, 100% feature-value consistency, and no measurable degradation of latency or throughput.
In a broader sense, this optimization project is an example of how we future-proof Binance’s infrastructure: by continuously rethinking how we use computing power, we can keep pace with rapidly evolving AI-driven abuse, strengthen real-time protection for users, and run a more sustainable, cost-efficient platform that’s ready for the next wave of growth.
Further Reading
Strategy Factory: Binance’s AI-Powered Rule Engine for Risk and Fraud Detection
Binance Leverages AWS Cloud to Enhance User Experience With Generative AI
Binance’s SAFUGPT – Unlocking AI Innovation with SAFU-Level Security
