You want to tokenize a $2 million villa. To put it on blockchain, you need to prove ownership. But what's your proof? A 47-page land registry PDF in Georgian, scanned from 1995 paper records, with handwriting and faded stamps.
Traditional oracles can't process this type of data. They only read JSON price feeds. But 80% of real-world data is unstructured: documents, images, audio, contracts. APRO's Multi-modal AI Pipeline is designed exactly for this problem - transforming unstructured real-world data into verifiable on-chain information.
THE PROBLEM: REAL-WORLD DATA ISN'T JSON
Traditional Oracles Work With Structured Data
Typical example - Price feed:
{
"asset": "BTC/USD",
"price": 42000,
"timestamp": 1701360000,
"source": "binance"
}
Clean, simple, machine-readable. Perfect for DeFi.
But Real World Assets (RWA) Are Completely Different
Real example - Real estate ownership proof:
27-page PDF scan from land registry
Handwriting mixed with printed text
Multiple languages (local language + English)
Stamps, signatures, watermarks
Tables with complex layouts
Cross-references to other documents
Insurance claim:
15-minute phone call audio recording
Smartphone damage photos (sideways, low quality)
69-page PDF policy document
Handwritten claim form
Legal contract:
20-page scanned PDF
Nested clauses with sub-sections
References to laws and regulations
Multiple party signatures
How can blockchain process these?
MULTI-MODAL AI PIPELINE: 4-STEP TRANSFORMATION
APRO's Layer 1 uses an AI pipeline to transform unstructured data → structured, verifiable format.
Step 1: Artifact Acquisition - Data Collection
"Artifact" = raw input data. Pipeline accepts multiple types:
Documents: PDFs (scanned or digital), Word docs, contracts, Government records, certificates
Images: Property photos; ID cards, passports; Receipts, invoices; Diagrams, technical drawings
Audio: Customer service calls; Legal proceedings; Insurance claim interviews
Web Data: Land registry websites; Public records; Court documents; With TLS fingerprints to verify authenticity
Example: Tokenizing real estate
Input: PDF land registry from Georgia government website
APRO node securely crawls document
TLS fingerprint: sha256:7f8a9b2c... proves document hasn't been tampered
Store artifact hash on-chain: 0xab12cd34...
Step 2: Multi-modal Processing - AI "Reads" Data
This is the core of the pipeline. A chain of AI models processes the data:
a) OCR (Optical Character Recognition)
Converts images/PDFs → raw text.
Technology:
Tesseract for open-source
PaddleOCR for multi-language
Modern: GPT-4 Vision, Mistral OCR (2000 pages/min)
Challenges:
Handwriting recognition
Low-quality scans
Mixed languages
Complex layouts (tables, diagrams)
APRO approach: Likely ensemble multiple OCR engines, pick highest confidence output.
b) ASR (Automatic Speech Recognition)
Audio → text transcripts.
Use case: Insurance claims
Customer calls: "My car was damaged in the accident on December 3rd..."
Agent response: "Can you describe the extent of the damage?"
Transcript feeds into analysis pipeline
Technology: Whisper (OpenAI), Google Cloud Speech-to-Text
c) NLP/LLM (Natural Language Processing)
Raw text → structured schema-compliant data.
d) Document Understanding - Context & Cross-Reference
LLM doesn't just extract text, but understands context:
Legal contracts:
Identify obligations of each party
Extract termination clauses
Flag compliance requirements
Financial documents:
Extract transaction details
Verify calculations
Detect anomalies
Cross-referencing:
Compare with public records
Verify consistency across multiple documents
Flag discrepancies
Example: Real estate
Extract owner name from land registry
Cross-check with government database snapshot (on-chain)
If mismatch → flag for manual review
Step 3: Structured Payload Generation
AI output is formatted into standardized schema.
Step 4: Cryptographic Signing
L1 node signs payload:
signature = sign(payload_hash, node_private_key)
This signature proves:
This node processed this data
Data hasn't been tampered since processing
Node accountable if data is wrong
PoR (Proof of Reserve) Report is sent to Layer 2 for consensus.
REAL USE CASE: REAL ESTATE TOKENIZATION
RWA tokenization market projected $16 trillion by 2030. Real estate represents $3-4 trillion.
Current Process (Without APRO):
Property owner wants to tokenize $2M villa
Hire lawyer to manually extract data from land registry PDF
Lawyer verifies ownership with government (weeks)
Notarize documents
Upload scanned copies
Smart contract mints token based on... trust in lawyer?
Cost: $10K-50K, Time: 4-8 weeks
With APRO Multi-modal AI:
Upload land registry PDF + appraisal report
APRO L1 AI pipeline:
OCR extracts all text (2 minutes)
NLP structures data into schema (1 minute)
Cross-reference with Georgia land registry snapshot on-chain (30 seconds)
Generate PoR Report with confidence scores
L2 consensus validates (PBFT, 2 minutes)
Smart contract mints token with verifiable metadata
Cost: $100-500, Time: <10 minutes
Savings: 100x cost reduction, 10,000x time reduction.
Real-World Examples:
Georgia's Ministry of Justice + Hedera:
Tokenizing entire national land registry
MoU signed December 2024
Millions of properties → on-chain
Oracle needed to process existing documents
Dubai + Hedera:
Land registry tokenization launched 2025
Prypco Mint platform
Tokens synced with official government database real-time
Problem both face: Existing records are PDFs, scans, handwritten documents from decades ago. Multi-modal AI oracle is the missing piece.
CHALLENGES & REALISTIC LIMITATIONS
AI Isn't 100% Accurate
OCR errors:
Handwriting: 85-92% accuracy (current best)
Low-quality scans: 75-88%
Mixed languages: 80-95%
NLP/LLM hallucinations:
Models can invent data when uncertain
Confidence scores help, but don't eliminate risk
Solution:
Human-in-the-loop for high-value assets (>$1M)
Multi-model consensus (3 LLMs vote)
Tiered confidence thresholds:
95% confidence → auto-approve
85-95% → automated review rules
<85% → manual review required
Context Understanding Limitations
AI can miss:
Legal nuances (jurisdiction-specific clauses)
Cultural context (naming conventions)
Implicit references (document says "as per previous agreement" - AI doesn't have previous agreement)
Solution:
Domain-specific fine-tuning
Legal expert validation layer
Dispute resolution mechanism in L2
Data Privacy Concerns
Processing PDFs with personal information (ID cards, addresses, financial data).
Risks:
AI models might store/leak sensitive data
Training data contamination
APRO approach:
Process in secure enclaves (TEE - Trusted Execution Environment)
On-chain only stores hashes and extracted structured data
Original documents stay off-chain, encrypted
Cost vs Accuracy Trade-off
High accuracy pipeline:
Multiple OCR engines (Tesseract + PaddleOCR + Mistral OCR)
Multiple LLMs (GPT-4 + Claude + Gemini) → vote
Extensive cross-referencing
Cost: $50-100 per document
Time: 10-30 minutes
Fast & cheap pipeline:
Single OCR engine
Single LLM
Minimal cross-checking
Cost: $1-5 per document
Time: 1-3 minutes
Accuracy: 80-90% (vs 95-98%)
APRO challenge: Balance cost vs accuracy based on use case.
COMPARISON WITH TRADITIONAL APPROACHES
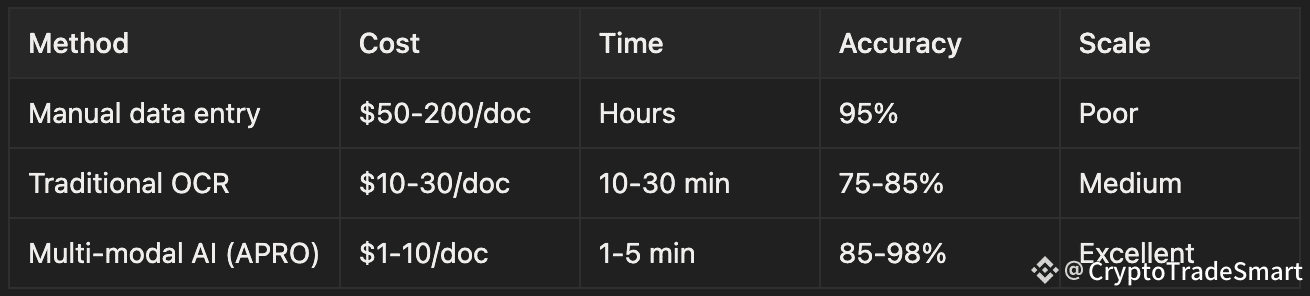
APRO's advantage: Scale + Speed + Cost efficiency.
WHY MULTI-MODAL MATTERS?
RWA Market = $16T Opportunity
But can only tokenize if there's a way to:
Verify ownership from unstructured documents
Extract valuation data from appraisal reports
Process legal contracts automatically
Create audit trail for regulators
Without multi-modal oracles, RWA tokenization is stuck in high-touch, manual processes - doesn't scale.
AI Applications Need Verified Real-World Data
AI agents are exploding. But they need:
Verified external data (not hallucinations)
Structured inputs from unstructured sources
Audit trails
APRO AI Oracle = infrastructure for AI-powered dApps.
CONCLUSION
Multi-modal AI Pipeline is real innovation in the oracle space. By combining OCR, ASR, NLP/LLM, APRO transforms unstructured real-world data into verifiable on-chain information.
Real estate tokenization is the killer use case: Georgia and Dubai have committed to migrating land registries to blockchain. Processing millions of existing documents manually? Not feasible. AI oracle is the only scalable solution.
But realistic expectations: AI isn't perfect. Confidence scores, human-in-the-loop for high-value assets, and dispute resolution mechanisms are all necessary. Good architecture, but execution at production scale will reveal edge cases.
👉 If tokenizing your house, would you trust AI to extract ownership data from paperwork? Or still want lawyer verification first?
#APRO #RWA #AI @APRO Oracle #WriteToEarnUpgrade #Tokenization


✍️ Written by @CryptoTradeSmart
Crypto Analyst | Becoming a Pro Trader
⚠️ Disclaimer
This article is for informational and educational purposes only, NOT financial advice.
Crypto carries high risk; you may lose all your capital
Past performance ≠ future results
Always DYOR (Do Your Own Research)
Only invest money you can afford to lose
Thanks for reading! Drop your comments if any!
