You're building a DeFi lending protocol. The critical question: How should the oracle update ETH price? Automatically every 10 minutes regardless of usage (Push)? Or only update when users actually need it (Pull)? This decision directly impacts gas costs, data freshness, and protocol security. APRO supports both models - but when should you use which?
PUSH MODEL: CONTINUOUS AUTO-UPDATE
How It Works
Push oracles operate like an automatic "heartbeat":
Trigger conditions:
Time-based: Update every X minutes (e.g., every 30 minutes)
Deviation-based: Update when price changes >Y% (e.g., >1%)
Hybrid: Combine both
Oracle operators automatically push data to a smart contract reference. This contract stores the latest price on-chain, ready for any protocol to read anytime.
Example - Chainlink Price Feed:
// Protocol just needs to read data
function getLatestPrice() public view returns (int) {
(,int price,,,) = priceFeed.latestRoundData();
return price;
}
Advantages
1. Always Available Data is always available on-chain. Protocols can read it instantly without additional transactions. Critical for lending protocols - when liquidating positions, can't wait for oracle updates.
2. Simple Developer Experience Developers just need to call one function. No need to worry about fetching data or paying oracle fees.
3. Predictable Data Freshness Know for certain data is updated on schedule. If heartbeat is 30 minutes, worst case data is 30 minutes old.
Trade-offs
1. Gas Cost Explosion Oracle operators must pay gas for every update, whether anyone uses it or not.
Chainlink example:
1 price feed update = ~$5-50 gas (depending on Ethereum congestion)
Update every 30 minutes = 48 updates/day
Cost: $240-2,400/day for just 1 feed
During high volatility:
Prices change rapidly → trigger many deviation updates
Gas costs spike to $100+ per update
RedStone report: "100,000s spent in short periods"
2. Limited Scalability High costs → limits number of:
Price feeds supported (typically 100-200 feeds)
Blockchains supported (must choose carefully)
Update frequency (trade-off between cost vs freshness)
3. Wasted Updates If no one uses data for 30 minutes, oracle still updates and pays gas. Inefficient.
PULL MODEL: ON-DEMAND UPDATES
How It Works
Pull oracles flip the script: Data is generated off-chain continuously, but only pushed on-chain when someone needs it.
Workflow:
Oracle signs price updates off-chain at high frequency (sub-second)
User/protocol needs data → fetch signed price from off-chain
Submit price + signature in transaction
Smart contract verifies signature on-chain
Use fresh data in same transaction
Example - Pyth Network:
// User must pull data first
function openPosition(bytes[] calldata priceUpdateData) public payable {
uint fee = pyth.getUpdateFee(priceUpdateData);
pyth.updatePriceFeeds{value: fee}(priceUpdateData);
// Now can use fresh price
PythStructs.Price memory price = pyth.getPrice(priceId);
// ... open position logic
}
Advantages
1. Cost Efficiency - Decouple Frequency from Gas
Key innovation: Oracle signs data off-chain 1000x/second (free). Only pay gas when actually pulling.
Example:
High-frequency trading app needs price every second
Pull model: User pays gas only when trading (maybe 10 trades/day)
Push model: Oracle pays 86,400 updates/day → prohibitively expensive
2. Unlimited Scalability
Thousands of price feeds? No problem - no gas cost increase
Hundreds of blockchains? Deploy anywhere Wormhole supports
Sub-second updates? Off-chain signing handles it
Pyth Network: 500+ price feeds across 70+ blockchains. Impossible with push model.
3. Freshest Possible Data Data can be as fresh as 200ms (Entangle) or sub-second (Pyth). Push oracles typically 10-30 minutes.
Trade-offs
1. User Pays Gas Pull model shifts gas cost from oracle operator → end user.
Implications:
User transaction has additional verification overhead
Slightly higher gas per transaction
Protocols can subsidize for users, but cost still exists
2. More Complex Integration Developers must:
Fetch price data from off-chain API
Include priceUpdateData in transaction calldata
Handle fee payment logic
Deal with potential failures (API down, invalid signature)
3. Data Not Always On-Chain Unlike push model, data isn't always available on smart contract. If protocol needs historical prices or automation (liquidations), requires additional infrastructure.
APRO'S DUAL TRANSPORT APPROACH
APRO doesn't force developers to choose one side. It supports both:
Push Mode (Foundational Data)
L2 consensus finalizes data
Automatically pushes to smart contract storage
Use case: DeFi protocols needing continuous availability
Cost: Shared across ecosystem
Pull Mode (High-Frequency)
L1 signs data off-chain at ultra-high frequency
Users pull on-demand
Use case: Trading apps, gaming, high-throughput dApps
Cost: Pay-per-use
Best of both worlds: Flexibility based on use case.
COMPARISON TABLE: PUSH VS PULL
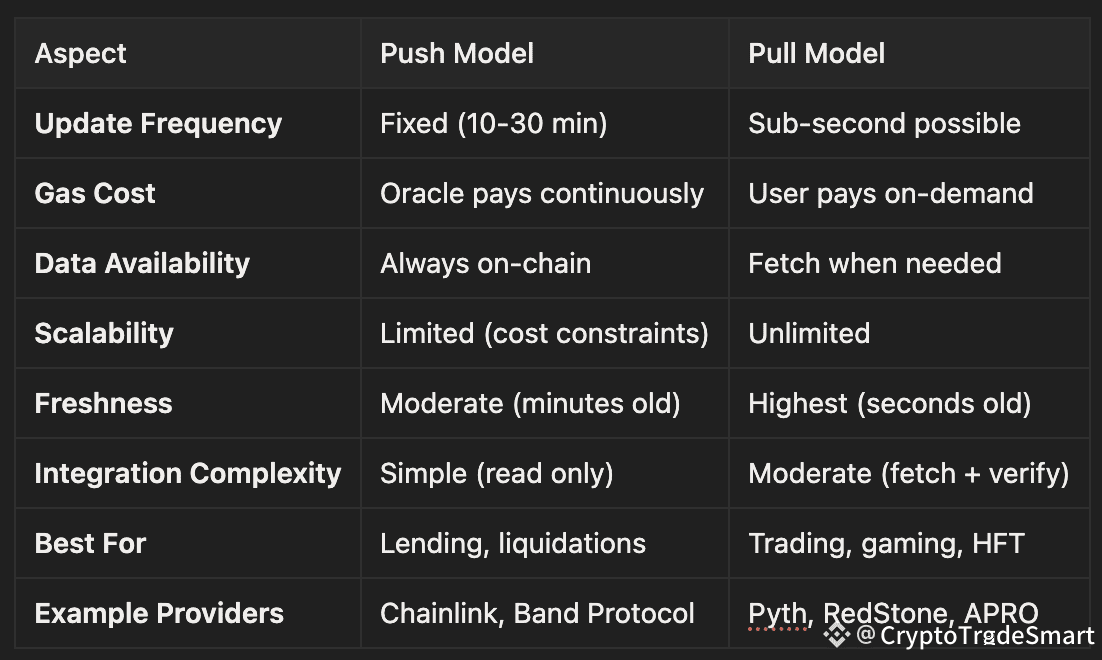
WHEN TO USE WHICH MODEL?
Use PUSH when:
✅ DeFi Lending/Borrowing
Aave, Compound need data always available for liquidations
Can't require liquidators to fetch oracle data
✅ Automated Operations
Liquidation bots, rebalancing, yield farming
Need smart contracts to check prices without human intervention
✅ Low-Frequency Updates OK
Insurance settlements (1x/day)
Staking rewards distribution (1x/epoch)
Use PULL when:
✅ High-Frequency Trading
Perps, derivatives, options protocols
Need sub-second price updates
Users are trading anyway → additional gas verification acceptable
✅ Cost-Sensitive Applications
Protocols on L1s with high gas (Ethereum mainnet)
Long-tail assets rarely traded
New protocols without revenue stream
✅ Gaming & NFT Minting
User-triggered actions
Pay-per-use model makes sense
Need real-time pricing
✅ Multi-Chain Expansion
Want presence on many chains
Push model economically infeasible to maintain 50+ chains
HYBRID STRATEGIES
Many modern protocols use a hybrid approach:
Example - Perp DEX:
Push oracle for base collateral assets (ETH, BTC) - always available
Pull oracle for long-tail assets (shitcoins) - on-demand
Result: Security + cost efficiency
Example - Lending Protocol:
Chainlink (push) as primary oracle
Pyth/APRO (pull) as fallback/verification
Cross-validate between 2 sources → extra security
CONCLUSION
Push vs Pull isn't a zero-sum game. It's trade-offs based on use case:
Push = Reliability & Simplicity, but Expensive & LimitedPull = Scalability & Freshness, but Complex & User-Paid
APRO's dual transport model allows developers to choose based on their needs. It's evolution in the right direction - there's no "one size fits all" in oracle design.
👉 Does your protocol need updates every 30 minutes (push) or every 200ms (pull)? Are users willing to pay extra gas for fresh data? Or does the protocol subsidize the cost?
@APRO Oracle #APRO #WriteToEarnUpgrade #BinanceBlockchainWeek


✍️ Written by @CryptoTradeSmart
Crypto Analyst | Becoming a Pro Trader
⚠️ Disclaimer
This article is for informational and educational purposes only, NOT financial advice.
Crypto carries high risk; you may lose all your capital
Past performance ≠ future results
Always DYOR (Do Your Own Research)
Only invest money you can afford to lose
Thanks for reading! Drop your comments if any!
