在很多人想象里,维护区块链安全的主力军,还是那些“用爱发电”的技术极客。但在更真实的加密世界里,安全往往是靠贪婪被正确引导来完成的。
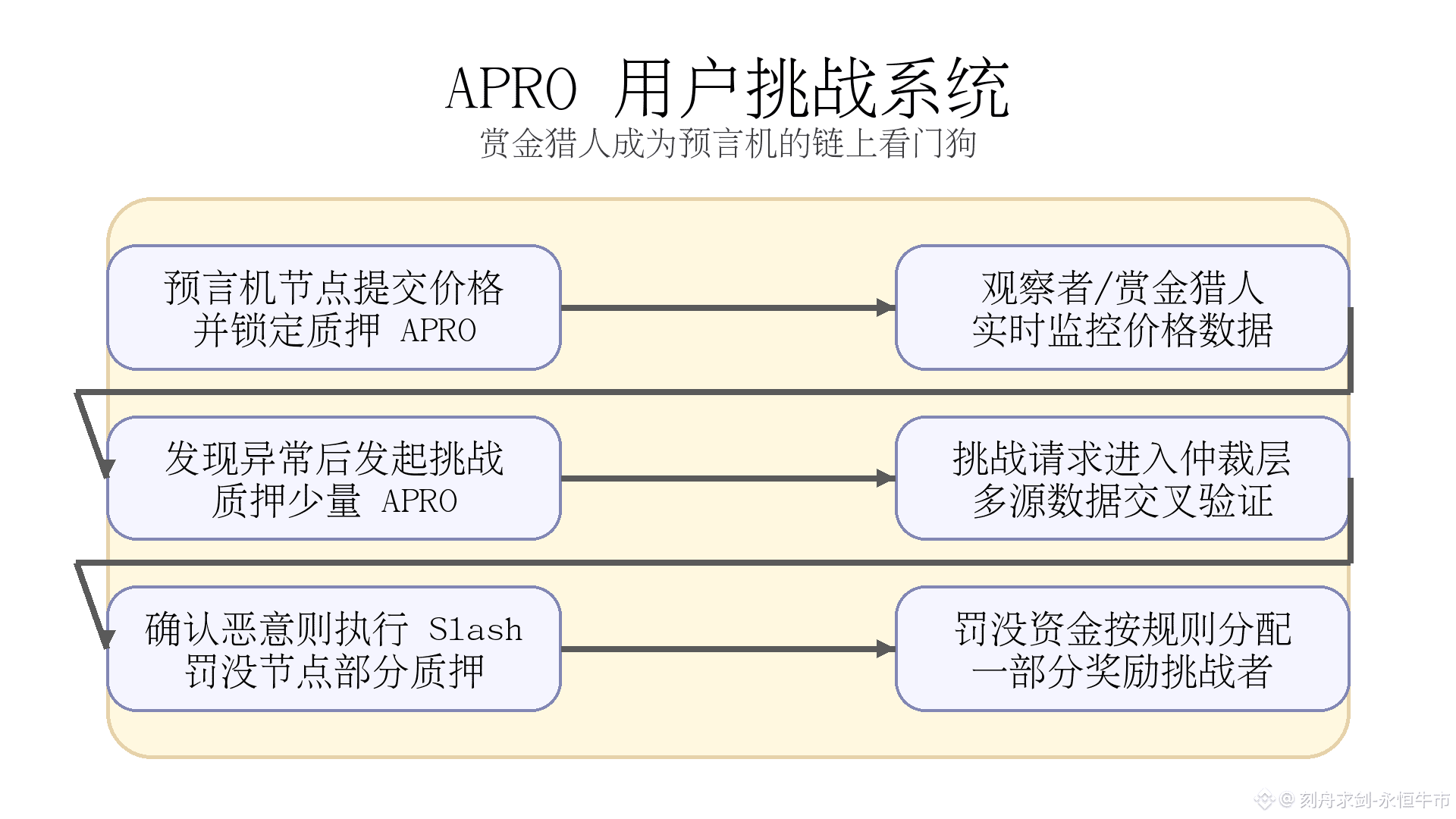
在 APRO 的设计中,所谓“用户挑战系统”,本质上是一套围绕预言机网络搭建的经济博弈机制:
不去假设每个节点都高尚;
而是默认所有参与者都逐利,然后用协议把这种逐利行为转化为安全性。
只要出现可疑数据,就会有人为了赏金去盯;只要挑战机制设计得足够精细,最贪婪的那批人,反而会成为 APRO 预言机最锋利的安全防线。
一、从“默认诚实”到“允许被挑战”的博弈结构
传统预言机更多依赖节点自律或中心化审核,一旦少数节点合谋,普通用户几乎无力介入。
APRO 采用的思路更接近 Optimistic Rollup:
默认:预言机节点上报的数据是正确的;
同时:在一个限定的挑战窗口期(Challenge Window)内,任何观察者都可以质押少量 APRO 发起挑战;
一旦挑战成功,恶意节点被 Slash,挑战者获得一部分罚没作为赏金。
这背后是典型的**激励相容(Incentive Compatibility)**设计:
节点为了赚取持续的预言机奖励,需要保持诚实,否则质押随时可能被削减;
用户 / 赏金猎人只要找到一次明显作恶,就可能获得远高于挑战成本的收益;
协议整体只需要在规则层面对“作恶”和“纠错”进行明确定价,就能让博弈长期朝着安全方向演化。
二、假如有一次“3% 偏差报价”,资金流会怎么走?
为了让机制更直观,我们用一个假设场景来拆解资金流(不是链上真实事件,只作为解释 APRO 机制的例子):
假如有一个 APRO 预言机节点,在 Polygon 上报了偏离市场 3% 的 USDT 价格,意图套利;
同时,有一个自动化脚本(类似“SniperBot”的 Watchtower)盯上了这条数据。
在 APRO 的挑战系统中,这场博弈的链上流程,大致可以抽象成下面这样:
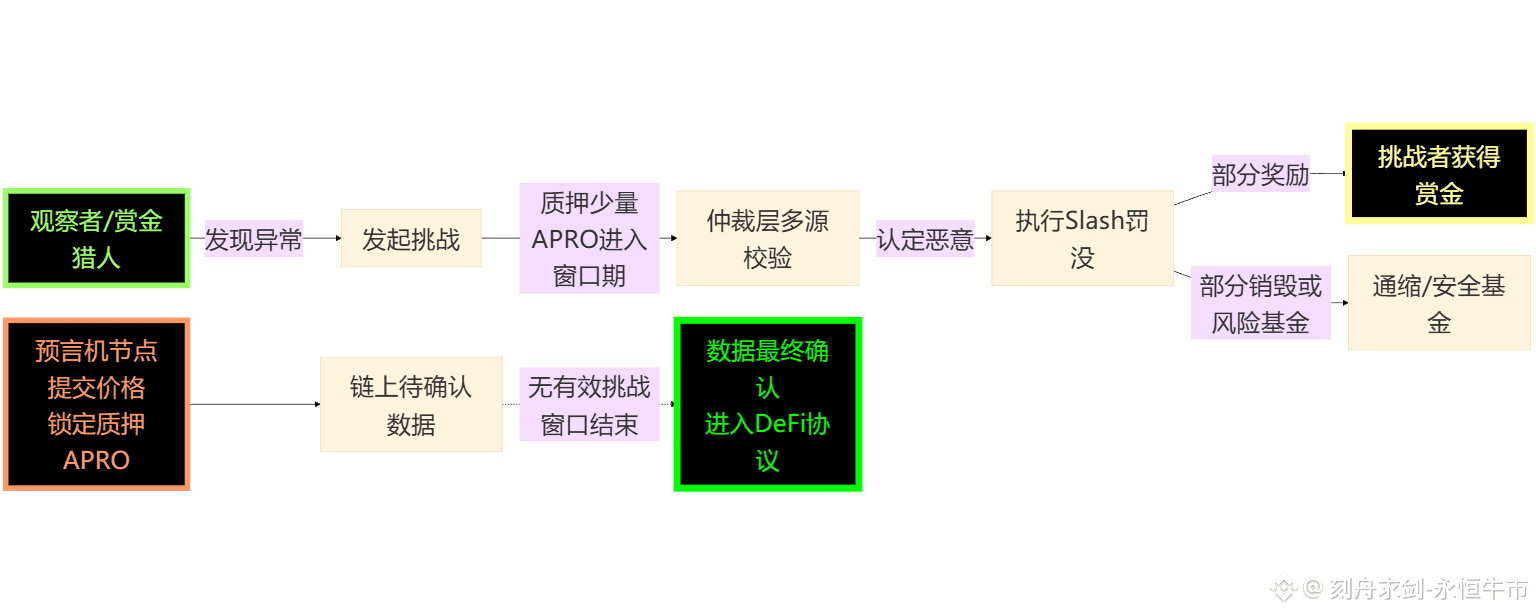
这里面的关键点有两个:
挑战者也需要质押
防止有人“乱扣帽子”滥用挑战接口;
挑战失败时,挑战者自己的押金会部分或全部被罚没。
Slash 的去向是协议安全的长期护城河
一部分作为赏金分给成功挑战方;
一部分直接销毁或进入安全基金,增强代币长期价值与网络抗风险能力。
简单说:
节点作恶,损失的是自己的质押和未来收入;
挑战者做对,获得一次性的正向激励;
协议整体,从每一次“抓包”中获得更强的安全信誉。
三、为什么这种“猎人模式”比内部风控更可靠?
中心化预言机或者内部风控团队,通常存在几个现实问题:
审计疲劳与人力瓶颈
内部安全团队不可能 7×24 小时盯住所有链、所有资产;
当监控规模增加,平均关注度必然被稀释。
潜在的合谋与道德风险
越重要的位置,越容易成为利益攻击目标;
单一组织掌控全部数据审核权,也更难让外部相信“完全中立”。
APRO 把思路反过来:
既然不可能消灭贪婪,那就把贪婪升级成系统的一部分。
任何人、任何团队,都可以运行属于自己的 Watchtower 或 SniperBot;
只要有足够收益预期,就会有人投入算力和时间去做这件事;
赏金猎人越多,APRO 的数据就越难被悄无声息地操纵。
这是一种典型的“猎人模式”:
协议不再依赖单一“守门人”;
而是鼓励所有人都成为守门人,用真实经济收益把安全外包给整个网络。
四、APRO 如何防止挑战机制被“反向利用”?
任何开放式挑战系统,都要面对一个问题:
如果大家为了赚赏金开始“乱挑战”,岂不是会把网络搞得鸡犬不宁?
APRO 在设计上一般会采用几层缓冲:
挑战成本 > 零成本噪音攻击
发起挑战必须抵押一定数量的 APRO;
一旦挑战被判定为无效或恶意,挑战押金会被部分扣减,用于补偿被挑战节点的成本。
仲裁层与多源数据交叉验证
挑战是否成立,不由单一节点说了算;
仲裁逻辑可以部署在类似 EigenLayer AVS 这样的验证服务上,通过多家行情源、历史数据和统计偏差来判断。
频繁失败的挑战者会被“降权”
如果某个地址在短时间内多次挑战失败,其挑战权重或上限可以被协议自动下调;
极端情况甚至可以被标记为潜在骚扰者,限制参与频率。
这样一来,只有有把握、有技术实力的猎人,才会持续参与挑战系统。
对普通用户来说,不参与也不会受损,但参与就有机会分享网络安全带来的收益。
五、这套机制对 APRO 的长期意义是什么?
从更高的角度看,APRO 的用户挑战系统解决的不是某一次错误报价,而是整个预言机网络的长期治理问题:
让“作恶成本”高于“作恶收益”
节点如果想通过一次错误报价获得套利,必须承担质押被 Slash 的风险;
只要扣罚额度设计合理,理性的节点会更倾向于老老实实赚长期激励。
让“主动监督”比“被动信任”更便宜
赏金猎人自发承担了监控成本;
协议通过赏金与销毁机制,把这部分成本再分摊回整个网络。
让安全性随网络规模正向增长
节点越多,运行的 Watchtower 越多,攻击者越难找到“盲区”;
TVL 越高,作恶收益越诱人,赏金空间也越大,反而吸引更多猎人加入守卫。
对持有 APRO 或依赖 APRO 数据的下游协议来说,理解这套用户挑战系统,等于看清了 APRO “安全溢价”的来源:
不是靠一句“我们很安全”,而是靠一整套写进智能合约里的博弈论设计。
六、理性提示
文中关于 APRO 及其挑战/赏金机制的场景描述,用于说明协议设计思路,部分为假设案例示意,并不对应特定链上真实事件。本文不构成任何投资建议或收益承诺,参与任何链上交互前,请务必自行研究(DYOR)并根据自身风险承受能力审慎决策。
我是刻舟求剑,一个只看本质、不追噪音的分析师。 @APRO Oracle #APRO $AT